

Avec cet article, j’ai envie de revenir aux bases. Aux bases des bases je devrais même dire  . J’ai envie de vous parler du fonctionnement d’un réseau informatique ! Vaste sujet…
. J’ai envie de vous parler du fonctionnement d’un réseau informatique ! Vaste sujet…
Dans cette introduction – que j’ai tenté de rendre « ludique » avec un genre de jeu de questions/réponses pour qu’elle soit accessible au plus grand nombre – nous allons donc parler des principaux éléments qui composent un réseau et expliquer dans les grandes lignes comment se passe un échange de données.
Découvrir les bases de la communication des machines en réseau
Cela faisait un moment que je n’avais pas fait « d’intro » sur un sujet en particulier et celui ci me trottait dans la tête depuis bien longtemps. Il était jusqu’à maintenant privé mais je me suis dit que ça pourrait intéresser plus de monde alors j’ai pris ma plume pour Neptunet (oui je suis poète des fois…).
Le « réseau » en informatique est au départ un monde très complexe (pas qu’au départ d’ailleurs). Avec cet article, j’avais envie que le plus de gens possibles tombent dedans et comprennent un peu mieux comment tout cela fonctionne, il a donc été rédigé de façon un peu différente de d’habitude pour être, je l’espère en tout cas, plus sympa et moins lourd.
Rassurez vous de suite, cet article sera simplifié le plus possible et accessible à tous. Vous y trouverez plein d’illustrations et de schéma pour mieux visualiser les choses. De plus, l’article ne traitant vraiment QUE les bases, il regorge de liens vers des ressources qui pourront intéresser les plus curieux d’entre vous.
Je vous souhaite une bonne lecture 
⇒ Accès rapide aux différentes parties de cet article :
1. Comprendre la notion de « réseau »
Dans ce premier chapitre, nous allons démarrer tranquillement en tentant de donner une définition simple d’un réseau.
Globalement, nous pouvons dire qu’un réseau est un « ensemble de relations ». Cela se matérialise par l’interconnexion de différents éléments les uns aux autres.
Un réseau permet la « liaison », ou la « mise en relation » d’éléments entre eux. Dans la vie de tous les jours, vous utilisez déjà constamment des réseaux :
Pour vous déplacer d’un point A à un point B, vous empruntez forcément le « réseau routier »…
… ou peut être que vous utilisez le « réseau ferroviaire »…

… vous utilisez également le « réseau d’eau potable » (j’espère pour vous en tout cas !)…

… vous usez et abusez bien évidemment du « réseau électrique »…

Et bien entendu vous sollicitez votre « réseau humain » ou « social », vos amis, proches, collègues…

Que ce soit en informatique ou en télécommunication, c’est exactement la même chose ! Un réseau informatique n’est rien d’autre que de nombreux éléments reliés ensemble et qui s’échangent des données.
Quand vous regardez une série en streaming, quand vous passez un appel depuis votre smartphone, quand vous jouez à des jeux vidéos, quand vous consultez l’actualité ou les réseaux sociaux, quand vous envoyez un mail…

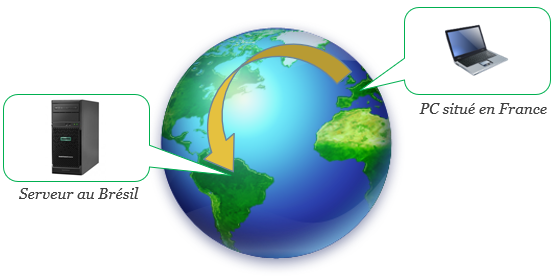
… vous utilisez le réseau numérique pour échanger des données. Plus précisément, votre équipement communique avec des machines (en général des serveurs rangés dans de grandes armoires aussi appelées baies) situées aux quatre coins de la planète.

Ces machines stockent vos données et vous permettent d’y avoir accès depuis n’importe où. Il y a donc bien un échange de données entre un point A (vous) et un point B (la machine qui stocke vos données).
2. A la conquête d’Internet
Quand on demande à une personne non informaticienne de définir ce qu’est « Internet », sa réponse est souvent que c’est « le web ». Non, le web est plutôt un énorme ensemble d’informations qui sont disponibles grâce à Internet, le web est ce qu’on appelle un « service ». Internet est en réalité le plus grand réseau au monde.
Et bien la réponse est OUI tout simplement s’il est relié à ce qu’on appelle « Internet ».
Internet est un ensemble de réseaux interconnectés ensemble. C’est donc un « réseau de réseaux » qui forme le plus grand réseau mondial.
Internet rend accessible à tous une multitude de services comme vous l’avez compris précédemment (messagerie, streaming, navigation web, transfert de fichiers…). Si votre PC est relié à Internet, il peut donc communiquer avec d’autres équipements situés partout sur le globe suivant ses besoins.
Pour relier votre PC à Internet, il va vous falloir un équipement qui fait le lien entre vous et le reste du monde.
Cet équipement se matérialise par la box (fibre, ADSL…) fournie par votre FAI (Fournisseur d’Accès Internet). Lorsque vous souscrivez un contrat chez un opérateur (Free, SFR, Orange…), vous payez le droit d’accéder librement à Internet depuis vos équipements personnels.
Tous vos équipements à la maison qui sont reliés entre eux vont former un mini réseau. La box va donc faire le lien entre votre réseau à vous, qui est privé, et le réseau Internet, qui lui est public.
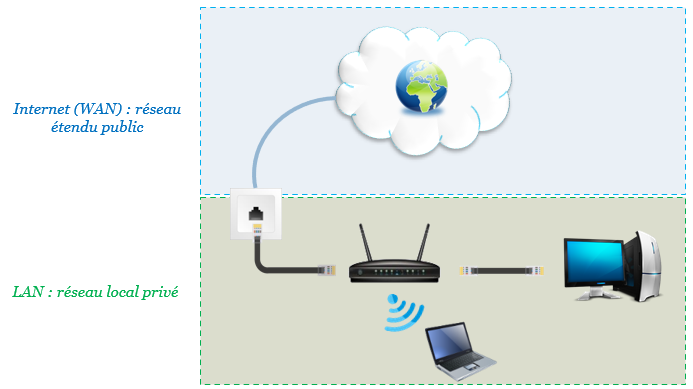
Voici une petite représentation de la façon dont votre réseau est relié à Internet :

Vos ordinateurs sont connectés à votre box via des ondes wifi ou un câble réseau (câble Ethernet RJ45).
Votre box est reliée chez vous par câble à une prise murale qui peut être soit une prise T (gigogne, ancienne prise téléphonique pour ceux qui sont restés au temps de Louis XIV), soit une prise RJ45 (comme illustrée sur l’image ci-dessus) ou alors à un PTO (Point de Terminaison Optique) pour la fibre optique.
Pour faire simple : cette prise murale ressort à l’extérieur de chez vous et se rend jusqu’à une grande armoire appartenant aux FAI appelée « répartiteur » (répartiteur NRA : Nœud de Raccordement d’Abonnés ou plus récemment NRO : Nœud de Raccordement Optique) qui peut être située à plusieurs kilomètres de votre domicile (oui ce sont des grands câbles )
Ce nœud de raccordement vous connecte finalement à Internet qui est représenté schématiquement en informatique par un nuage.
OUI c’est exactement ça ! Des équipements chez vous qui peuvent communiquer entre eux forment un réseau.
Ce réseau est privé car par défaut personne ne peut rentrer à l’intérieur sans autorisation spécifique. Quand il s’agit d’un réseau privé, on parle de « réseau local », ou « LAN » (Local Area Network). Le LAN est tout ce qui se trouve derrière votre box.
Pour le réseau Internet, on parle de « réseau étendu », ou « WAN » (Wide Area Network), car il couvre une grande zone géographique (la planète entière pour Internet). Le WAN est tout ce qui se trouve devant votre box.
3. Les équipements qui composent un réseau
Dans cette partie nous allons voir ensemble les différents matériels que l’on peut trouver dans un réseau et commencer d’expliquer comment ils communiquent entre eux.
Dans un réseau on peut trouver une multitude de matériels ! En réalité on peut trouver un peu tout et n’importe quoi du moment qu’il est possible de « connecter » l’équipement. Voici quelques exemples de périphériques, en général les équipements les plus connus du grand public :

Tout lister serait impossible mais sachez que tout ce qui est intelligent peut être mis en réseau : Compteurs, prises, interrupteurs, éclairage, alarmes, capteurs, sondes, électroménager (frigo, four, cafetière, machine à laver…), portails, tondeuses, véhicules, montres, brosses à dents, radiateurs…
Mais tous ces équipements ne sont que la partie émergée de l’iceberg. On les appelle les « périphériques finaux » car ils utilisent le réseau mais ils ne servent pas à grand-chose sans matériels spécifiques leur permettant de communiquer entre eux.
Voici maintenant une brève présentation des éléments les plus importants dans un réseau :

Le routeur est l’équipement qui permet à différents réseaux de communiquer entre eux. Votre box par exemple, est un routeur puisqu’elle relie votre réseau privé au réseau Internet. Si vous n’avez pas de routeur, les équipements de votre réseau ne pourront pas en sortir. On parle de « passerelle » pour désigner le routeur. C’est précisément par cet équipement que tous les autres du réseau devront passer pour en sortir. Il peut être filaire ou wifi.
 Le switch, ou commutateur en français, permet aux équipements d’un même réseau de communiquer entre eux, en « interne » on pourrait dire. Il faut le voir un peu comme la « multiprise » du réseau. C’est un matériel avec plusieurs ports permettant de brancher plusieurs équipements. Par exemple, dix ordinateurs branchés par câble Ethernet à un switch vont pouvoir s’échanger des données entre eux sans avoir besoin de sortir du réseau. Un switch peut également faire office de routeur si sa configuration lui permet. Votre box, une fois encore, est également un switch.
Le switch, ou commutateur en français, permet aux équipements d’un même réseau de communiquer entre eux, en « interne » on pourrait dire. Il faut le voir un peu comme la « multiprise » du réseau. C’est un matériel avec plusieurs ports permettant de brancher plusieurs équipements. Par exemple, dix ordinateurs branchés par câble Ethernet à un switch vont pouvoir s’échanger des données entre eux sans avoir besoin de sortir du réseau. Un switch peut également faire office de routeur si sa configuration lui permet. Votre box, une fois encore, est également un switch.

Les serveurs ont pour mission de fournir des services (stockage de données, sites internet, sécurité, centralisation d’accès…) qui seront accessibles sur l’ensemble du réseau. Un serveur est un ordinateur, à la différence qu’il est beaucoup plus puissant en terme de ressources matérielles (RAM, CPU…) et qu’il est conçu pour ne jamais être arrêté (ou le moins possible…). Les périphériques finaux (vus dans la slide précédente), sont justement ceux qui vont utiliser les services fournis par un serveur (un périphérique final peut aussi être un serveur).

Le firewall, ou pare-feu en français, est un élément très important dans un réseau puisqu’il va permettre de protéger très finement les entrées et les sorties de votre réseau privé. Un firewall peut prendre différentes formes, ça peut être un boitier ressemblant à un routeur, une machine virtuelle, un serveur… Il est impératif en entreprise et se place en général derrière le routeur principal (c’est en gros un second routeur). Il va autoriser ou refuser certains flux pour garantir la sécurité du réseau et lutter contre les intrusions (exemple, autoriser à sortir sur le web mais pas à faire de la visio).
D’autre équipements peuvent venir se greffer sur un réseau et sont plus ou moins importants pour les entreprises :

Le hub, ou concentrateur en français, est l’équivalent d’un switch mais nous pouvons dire en « moins intelligent ». Vous comprendrez pourquoi dans la suite de cet article. Pour le coup, c’est vraiment une simple « multiprise » utilisée quand on a besoin de quelques ports réseau en plus que ce qu’offre le switch ou la box internet. Cet équipement n’est quasiment plus utilisé et est remplacé au profit du switch.

La borne wifi, pouvant être un « point d’accès wifi », un « routeur wifi », ou un simple « répéteur », c’est à dire un amplificateur du signal wifi dans une zone mal couverte. Cet équipement permet justement de déployer du réseau sans fil là où l’on a que du filaire, ou encore d’élargir la zone de couverture d’un réseau sans fil déjà existant. Il est relié par câble à un switch et transforme le signal filaire en ondes. Attention, un point d’accès sans fil n’est pas forcément un routeur wifi.

L’onduleur est un équipement à ne pas négliger, surtout en entreprise. Il transforme le courant continu en courant alternatif. C’est-à-dire qu’il va en quelques sortes « simuler » de l’électricité pendant une courte période (quelques minutes en général). Il protège les machines de coupures électriques imprévues qui pourraient mettre à mal des équipements réseau, surtout les serveurs qui ne doivent pas être arrêtés et encore moins violemment…
Parce qu’ils ont tous obligatoirement une chose en commun : une carte réseau.
La carte réseau est le composant électronique qui permet de faire le lien entre l’équipement dans lequel elle est installée et le réseau auquel celui-ci est connecté.
Pour fonctionner, une carte réseau a besoin de deux éléments :
- Une adresse MAC (Media Access Control), qui est son identifiant physique permettant de la reconnaître matériellement parmi d’autres carte réseau. Une adresse MAC est censée être unique au monde et elle est définie par le constructeur, vous n’avez rien à faire en général.
- Une adresse IP (Internet Protocol), qui est son identifiant logique, c’est-à-dire virtuel, qui permet de la reconnaître dans un réseau. L’adresse IP doit être unique dans un réseau et c’est à VOUS de la définir (grâce à un service préconfiguré appelé DHCP ou manuellement). Sans adresse IP, la communication entre machines ne sera pas possible.

Vous pouvez voir les adresses IP et MAC de votre carte réseau avec la commande « ipconfig /all » sous Windows ou « ip a » sous Linux lancée dans un terminal.
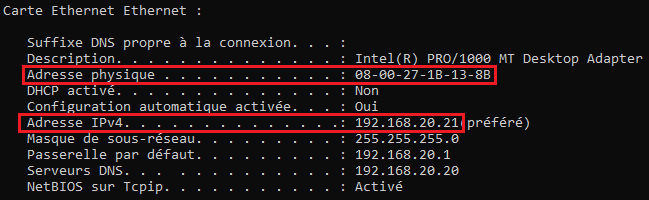

Une carte réseau peut être dite « filaire », c’est à dire qu’il faut y brancher un câble Ethernet (RJ45) qui sera relié à un switch ou alors sans fil (Wifi). Certaines cartes réseau sans fil peuvent avoir besoin d’antennes pour fonctionner.
4. L’importance des normes et des protocoles
Dans ce 4ème chapitre, vous allez découvrir que l’informatique est un monde plein de normes et de règles à respecter pour que les communications se passent pour le mieux.
A. Utilisation réglementaire des adresses IP
Commençons d’abord par parler des adresses IP, c’est le plus facile
NON pas vraiment. En fait dans l’IPv4, il existe ce qu’on appelle des « classes d’adresses IP ». Ce sont des plages d’adresses dont certaines sont réservées à des usages précis, on ne fait donc pas ce qu’on veut.
Une adresse IPv4 se décompose en 4 parties chacune séparées par un point. Par exemples, 1.1.1.1 est une adresse IP, 238.12.96.147 en est une autre, 192.168.1.99 encore une autre, etc…

Entre chaque point, le nombre peut aller de 0 à 255, jamais plus de 255. Ce qui veut dire que les adresses IPv4 vont de 0.0.0.0 pour la plus petite, jusqu’à 255.255.255.255 pour la plus grande.
Il existe 5 classes d’adresses IPv4 qui vont découper cette plage entre 0.0.0.0 et 255.255.255.255. Chaque classe est identifiée par une lettre de l’alphabet :
| Classe | Adresse de début | Adresse de fin | Particularité |
| A | 0.0.0.0 | 127.255.255.255 | Classe contenant des adresses publiques et privées. Les adresses en 127 sont réservées pour des tests dits de « boucle locale ». L’adresse 0.0.0.0 est réservée et matérialise ce qu’on appelle une « route par défaut » |
| B | 128.0.0.0 | 191.255.255.255 | Classe contenant des adresses publiques et privées. |
| C | 192.0.0.0 | 223.255.255.255 | Classe contenant des adresses publiques et privées. |
| D | 224.0.0.0 | 239.255.255.255 | Classe réservée pour le multicast (diffusion de données vers un groupe de machines précises) |
| E | 240.0.0.0 | 255.255.255.255 | Classe réservée par des entités informatiques (IETF, IANA, ICANN…) |
Comme vous pouvez le voir dans ce tableau, certaines plages d’adresses sont réservées, il n’est donc pas possible de les utiliser directement.
Ces classes ont été créées à la base dans un but surtout organisationnel en fonction des tailles de réseau, c’est plutôt une pratique désuète aujourd’hui surtout avec l’IPv6 mais il est néanmoins important de connaître ce système de classes d’IP car cela n’empêche pas que vous ne pouvez pas choisir les adresses IP que vous voulez.
Une fois encore, la réponse est NON pas vraiment. Il faut bien comprendre qu’il existe des adresses IP dites « publiques », c’est-à-dire qui sont joignables depuis le monde entier (réseau WAN) qui sont réservées pour la communication sur Internet que vous ne pouvez pas utiliser, et d’autres qui sont dites « privées », qui sont réservées à la communication dans un réseau local (réseau LAN), elles ne sont pas accessibles directement depuis l’extérieur du réseau. Votre box Internet possède une adresse IP publique et une adresse IP privée également car elle est située sur les deux réseaux, le WAN et le LAN.

|
Pour aller plus loin : Si vous souhaitez connaître votre adresse IP publique, qui est attribuée directement par votre fournisseur d’accès à Internet, vous pouvez regarder dans la configuration de votre box ou sur un site web tel que mon-ip.com |
Dans les 5 classes d’IP vues précédemment, vous pouvez choisir celles que vous voulez mais parmi des plages bien précises qui sont « privées ». Vous pouvez donc choisir des adresses IP privées comprises dans les plages suivantes :
-
-
-
- A. De 10.0.0.0 à 10.255.255.255
- B. De 172.16.0.0 à 172.31.255.255
- C. De 192.168.0.0 à 192.168.255.255
-
-
L’intérêt des classes d’IP est de choisir une plage selon vos besoins. Plus votre réseau est grand et plus vous avez besoin d’adresses IP donc vous allez choisir une classe B par exemple. Si vous avez un petit réseau, comme votre réseau domestique, vous allez plutôt avoir une classe C. Cela permet tout simplement une meilleure optimisation de l’adressage IP.
La taille d’un réseau, et donc le nombre de machines que l’on peut mettre dedans (et par conséquent le nombre d’IP dont on a besoin) se calcule grâce à ce qu’on appelle le masque de sous-réseau qui est un élément indissociable d’une adresse IP. Le masque de sous-réseau permet de distinguer la partie « Réseau » et la partie « Hôte » d’une adresse IP (la partie hôte étant la machine a laquelle l’IP est attribuée, plus on peut mettre d’hôtes, plus le réseau est grand). Nous reviendrons brièvement sur ce point un peu plus tard.
Il existe d’autres adresses que vous pourrez rencontrer dans vos réseaux telles que 127.0.0.1 (boucle locale ou aussi appelée « localhost », chaque machine possède cette IP qui renvoie tout simplement sur elle-même) ou 169.254.x.x (adresse « APIPA » si aucune adresse IP n’est disponible sur le réseau et qu’une IP n’a pas été définie manuellement sur la carte réseau). Elles sont attribuées automatiquement, vous ne pouvez pas les attribuer.
/!\ Une adresse IP doit être unique dans un réseau. Si elle est déjà utilisée, vous provoquerez des conflits d’adresses IP qui peuvent empêcher des machines de fonctionner correctement. Il faut bien établir un plan d’adressage IP complet avant d’attribuer des adresses et le maintenir à jour.
OUI bien sur ! En informatique comme dans n’importe quoi, il faut des règles pour que tout fonctionne correctement. La preuve, vous venez de voir que vous ne pouvez pas utiliser n’importe quelles adresses IP chez vous…
En informatique, on parlera plutôt de « normes ». C’est un monde plein de normes qu’il faut respecter pour que tout se passe bien. La communication en réseau est régie par des ensembles de règles appelées « protocoles ». Un protocole décrit comment doit se comporter telle machine ou tel logiciel afin que tout communique dans les règles de l’art. Par exemple, il existe plusieurs protocoles concernant le comportement de la messagerie électronique ou encore la navigation sur Internet. Chaque créateur de protocoles ou constructeur de matériel doit veiller à ce que sa création respecte les protocoles existants, et donc par conséquent les normes en vigueur, sous peine qu’elle ne puisse jamais voir le jour…
Il existe de nombreux organismes mondiaux chargés de définir les normes et les standards que l’on utilise (même sans le savoir) sur Internet. Il existe par exemples l’IOS (International Organization for Standardization qui n’a rien à voir avec Apple donc on se calme les bouffeurs de pommes !) ou encore l’IETF (Internet Engineering Task Force).
Les organismes alimentent ce qu’on appelle les « RFC » (Request for comments), qui sont des documents contenant des informations techniques précises sur les protocoles, le réseau, le matériel… bref énormément de choses ! Attention cependant, les RFC ne sont pas toutes des normes obligatoires, certaines sont uniquement des recommandations, un peu comme les recommandations de l’ANSSI (Agence Nationale de la Sécurité des Systèmes d’Information) concernant la sécurité informatique. En résumé, les RFC ne sont pas des textes de lois, mais sont toutes aussi imbuvables… 
|
Pour aller plus loin : Consultez le lien suivant pour voir en gros à quoi ressemble une RFC (exemple pour l’Internet Protocol) : RFC791 |
B. Le modèle OSI
Voyons maintenant un des fondements de la communication dans un réseau informatique : le modèle OSI (accrochez vous à vos slips, ça peut piquer un peu )
Le modèle OSI est une référence en matière « d’Interconnexion des Systèmes Ouverts » (OSI in english). Plus simplement, le modèle OSI permet de bien comprendre et définir comment la communication doit s’effectuer dans un réseau.
C’est un modèle dit « en couches », ou chaque couche permet de visualiser une phase, une étape, lors de la communication de 2 machines ensemble. Le modèle OSI comprend 7 couches, la couche la plus basse étant toujours la première couche et la plus haute la septième dans l’ordre de numérotation. Voici comment il est représenté :

Chaque couche a une mission bien précise en matière de communication réseau. L’intérêt d’un modèle en couche est de mieux visualiser les interactions entre les différentes étapes du processus d’échange de données mais aussi d’éviter les problèmes car chaque couche est indépendante et ne peut communiquer qu’avec une couche adjacente (celle juste au dessus d’elle ou celle juste en dessous).
Lorsque deux machines s’échangent des données, ces données vont parcourir chacune des couches par étapes successives et à chaque fois subir un traitement particulier. On parle d’un processus « d’encapsulation » des données. Cela signifie que chaque couche ajoute aux donnés un « entête » avec des informations qui lui sont propres comme par exemple quel protocole doit être utilisé à cette étape précise pour communiquer.
Imaginez que lorsque vous envoyer une lettre à un ami, la poste ajoute à chaque fois une enveloppe en plus sur votre lettre. Une enveloppe indiquant le pays, l’autre la ville, l’autre la rue, l’autre le nom, etc… Et pour pouvoir lire votre lettre, votre ami doit enlever toutes les enveloppes…
Le modèle OSI est une ancienne norme qui est aujourd’hui obsolète. La norme utilisée de nos jours, notamment sur Internet, est le modèle TCP/IP. En revanche, OSI étant une base du modèle TPC/IP, elle reste incontournable. OSI est plutôt dit « théorique » pour comprendre le fonctionnement de base d’un processus d’échange de données dans un réseau, c’est pour cela qu’on parle de modèle de « référence ».
Chaque couche joue un rôle important dans le processus d’échange de données, d’ailleurs avec OSI, on ne parle pas de « données » mais plutôt « d’unité de données » (abrégé PDU), car le nom d’un message échangé varie d’une couche à une autre.
Une couche est associée à des protocoles qui régissent comment les données doivent être traitées. Par exemple elles définissent tout simplement si les données sont échangées via un câble réseau ou des ondes wifi, si l’échange est un envoi de mail ou la consultation d’un site web ou encore plus important, qui est l’expéditeur et qui est le destinataire de ces fameuses données… C’est pour ça qu’il est important de toutes les parcourir et toujours de haut en bas, ou de bas en haut dans l’ordre. Voici un schéma simple du rôle de chaque couche, le nom du message quand il parcourt cette couche (PDU) et des exemples de protocoles associés (n’oubliez pas que vous pouvez cliquer sur les illustrations pour agrandir) :
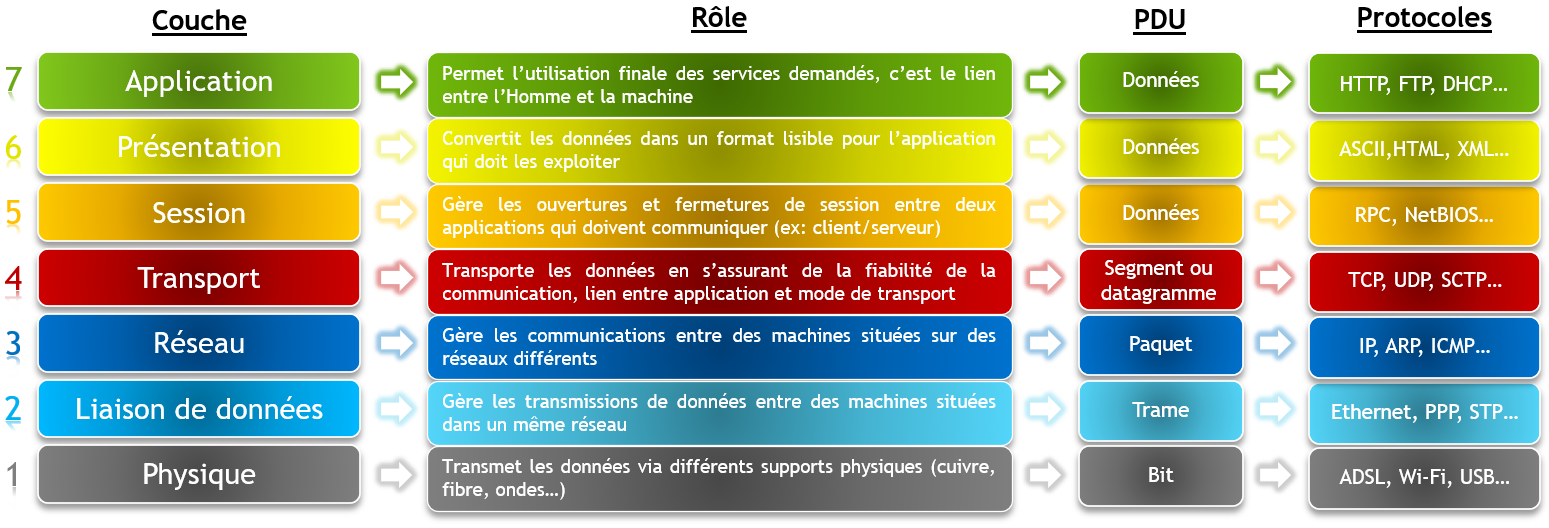
Oui c’est exactement ça, c’est le principe de l’encapsulation ! OSI est un peu comme un système de poupées russes finalement.
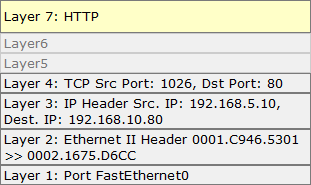
A chaque fois qu’une donnée passe par une couche, cette dernière lui ajoute un « entête » avec des informations qui lui sont propres. Par exemple, quand le message passe par la couche 7 Application, l’entête va contenir, entre autres, le protocole à utiliser, plus simplement à quelle application on veut parler (un site web ? Une messagerie ? Une base de données ? Etc…). Quand il arrive sur la couche réseau, l’entête ajoutée par la couche 3 va venir préciser l’adresse IP de la source, donc la machine qui émet le message, mais aussi l’adresse IP de destination, donc la machine qui doit recevoir le message. Et ainsi de suite jusqu’en bas du modèle OSI.
La donnée va traverser plusieurs équipements réseau afin d’arriver à destination qui vont chacun consulter l’entête de la couche qui les intéresse. Un routeur par exemple se moque de savoir l’application qui est ciblée. Un switch se moque de savoir le mode de transport utilisée, etc… Chacun son job !
Et une fois que le message a atteint sa cible (destination donc), les couches du modèle OSI vont cette fois ci être montée une à une. Le processus d’encapsulation va faire l’inverse, c’est-à-dire décapsuler les entêtes une à une pour avoir les informations nécessaires (décapsuler ou désencapsuler ? Petit doute…  ). Quand la destination répond à la source, le message va redescendre les couches, puis remonter, puis redescendre, puis remonter… et la boucle recommence éternellement.
). Quand la destination répond à la source, le message va redescendre les couches, puis remonter, puis redescendre, puis remonter… et la boucle recommence éternellement.
|
Pour aller plus loin : L’outil Cisco Packet Tracer en mode Simulation nous permet de voir ce qui se passe sur chaque couche du modèle OSI mais aussi le contenu des PDU.
Alors soyez curieux et testez cette outil (et aimez l’anglais aussi…), cet article vous aidera à le prendre en main : Introduction au logiciel Cisco Packet Tracer |
En gros oui ! En réalité, les couches 1, 2 et 3 du modèle OSI sont dites couches « basses » ou « matérielles » car elles peuvent être associés à des éléments physiques (câble, routeur…). Les 4 autres sont les couches « hautes » ou « logicielles » car liées à des protocoles et applications. Certains équipements ont une mission spécifique, il ne sert à rien par exemple pour le routeur de monter toutes les couches car il n’utilise que les adresses IP (IP est un protocole de couche 3 pour ceux qui n’ont pas regardé attentivement les images précédentes…), donc le message, arrivé au routeur, ne montera que 3 couches et redescendra aussitôt pour poursuivre sa route. Le switch lui n’utilise que les 2 premières couches.
Les données échangées entre 2 machines partent toujours de la couche 7 application. Le message va ensuite descendre toutes les couches, passer dans des câbles ou des ondes, remonter/descendre certaines couches à chaque fois qu’il rencontre un équipement réseau, pour une fois arrivé chez le destinataire, les remonter jusqu’à la couche 7 pour qu’une autre application lise le message :
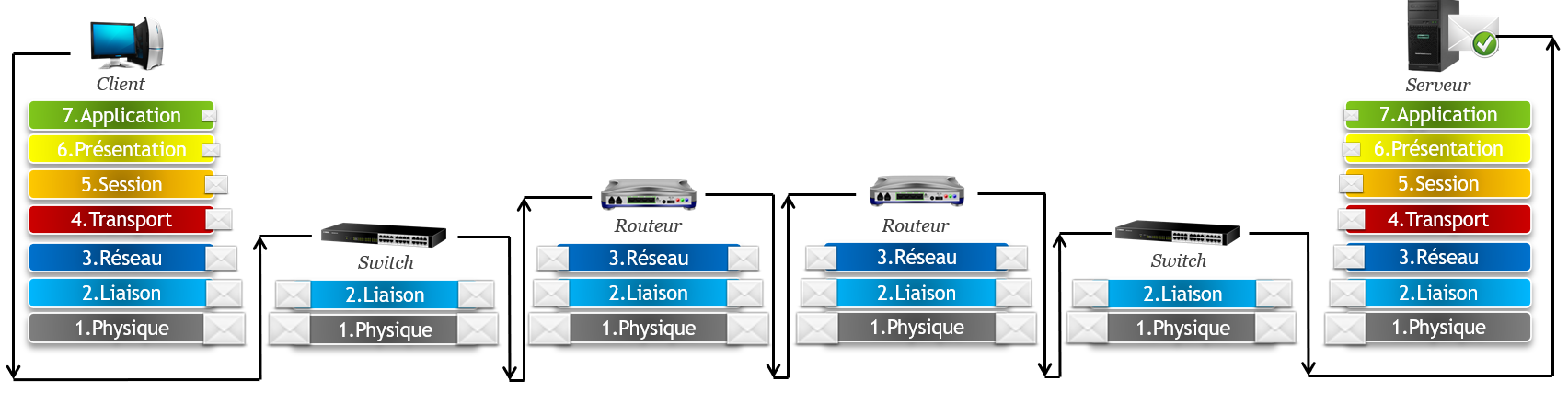
Dans cette illustration, le trait noir représente le chemin d’un message qui part d’un PC en direction d’un serveur. Les deux machines sont reliées l’une à l’autre par plusieurs switch et routeurs, comme sur Internet.
Si vous regardez l’enveloppe, vous verrez qu’elle est de plus en plus grosse car le message est de plus en plus gros vu que chaque couche « encapsule » les données et y ajoute ses propres informations en entête. Quand le message remonte, il rétrécit car chaque couche va cette fois-ci décapsuler les données et ainsi de suite jusqu’à destination où sera retrouvé le message original.
|
Pour aller plus loin : Pour en apprendre plus sur le modèle OSI, c’est par ici : Introduction au modèle OSI |
Le modèle OSI est un modèle qui a été jugé trop théorique, contraignant et pas assez précis lors de la création d’Internet. Le modèle TCP/IP est le modèle qui a été techniquement adopté et en vigueur aujourd’hui. Il ressemble à s’y méprendre à OSI, à la différence que les couches 5 Session, 6 Présentation et 7 Applications ont été regroupées en une seule et même couche nommée « Application ».
Le modèle TCP/IP actuel est composé de 5 couches dont les rôles sont plus ou moins identiques au modèle OSI.
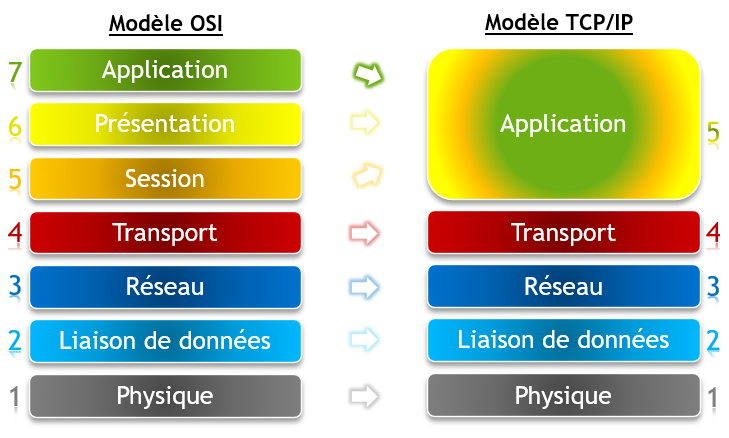
|
Info + : Il existe une variation en 4 couches de TCP/IP qui est une version un peu moins moderne mais similaire en fonctionnement. Dans cette version, les couches 1 et 2 d’OSI sont elles aussi regroupées en une seule couche appelée « Accès réseau ». La variante en 5 couches est dite « hybride » et est celle utilisée sur Internet. |
Ce qu’il est important de retenir c’est que OSI est un modèle dit « conceptuel » qui décrit comment doit se faire la répartition des tâches lors d’une communication réseau pour que ce soit opérationnel.
TCP/IP lui est un modèle « usuel » qui décrit les fonctionnalités précises nécessaires lors de cette communication. Il vient détailler justement qui fait quoi, où, quand, comment… ce que OSI n’explique pas. OSI donne seulement les idées en gros.
|
Pour aller plus loin : Pour en apprendre plus sur le modèle OSI, voici 2 liens tops : MODÈLE TCP/IP et MODÈLE OSI VS MODÈLE TCP/IP |
Si vous avez bien compris que les normes sont le ciment d’une bonne communication en réseau, alors nous pouvons passer à du concret et rentrer plus profondément dans le processus d’échange de données. 
5. L’échange de données entre équipements
Si vous avez survécu jusqu’ici, félicitations ! Le sujet du réseau est vaste et pas toujours super intéressant mais c’est important d’avoir quelques bases dans ce domaine. Dans cette partie, nous allons voir ensemble comment les données transitent entre les différents équipements réseau.
Déjà pour commencer, vous aurez compris que pour communiquer en réseau, les machines utilisent des adresses IP.
Une adresse IP en elle-même ne représente pas grand chose si elle n’est pas suivie d’un « masque de sous-réseau ». Ce masque est obligatoire car il permet de définir sur quel réseau se trouve une adresse IP. Comme dit précédemment, il délimite dans une adresse IP la partie « réseau », de la partie « hôte », c’est à dire l’adresse de la machine. Vous le verrez écrit de l’une ou l’autre de ces façons :
-
- Notation décimale : 255.255.0.0 ou 255.255.255.0, etc… En décimal un masque peut aller de 0.0.0.0 à 255.255.255.255
- Notation CIDR : /16 ou /24, etc… En CIDR, un masque peut aller de /0 à /32.
|
Info + : 0.0.0.0 à 255.255.255.255 ou /0 à /32 sont des masques « globaux » que vous ne pouvez pas vraiment utiliser car ils correspondent respectivement à une ip qu’on pourrait dire « indéterminée » (ou qualifiée de « partout » c’est pour cela que 0.0.0.0 est appelée route par défaut) pour la plus basse et au broadcast universel qui englobe l’intégralité des adresses IPv4 pour la plus haute, les masques réellement utilisables sont de 128.0.0.0 à 255.255.255.254 ou /1 à /31. Attention toutefois, l’adresse d’un masque de sous-réseau écrite en décimal est précise, il n’existe que peu de possibilités que vous pouvez retrouver dans ce document : Correspondance masque décimal/CIDR |
Pour comprendre le principe, redescendons encore un peu plus dans les bases…
L’unité de donnés en informatique s’appelle le « bit ». C’est le langage utilisé par les ordinateurs que nous ne pouvons pas comprendre en tant qu’humain. Pour les IP, nous utilisons donc des chiffres, plus classiques, mais que l’ordinateur sait comment interpréter dans sa propre langue.
Un bit peut être soit un 0, soit un 1 et rien d’autre. 8 bits forment ensemble 1 octet.
Pour rappel, une adresse IPv4 est composée de 4 parties séparées par des points. Chaque partie est 1 octet. 8bits x4 = 32bits au total, une adresse IPv4 est donc codée sur 32 bits d’où le « /32 » maximum.
Si le masque est en /24, cela signifie que le réseau prend 24 bits et l’hôte 8 bits, soit 3 octets pour identifier le réseau et 1 octet pour identifier la machine dans ce réseau. Ce calcul est assez simple à faire de tête avec le temps mais dans certains cas, une connaissance du système binaire est incontournable.
Un petit exemple en image :
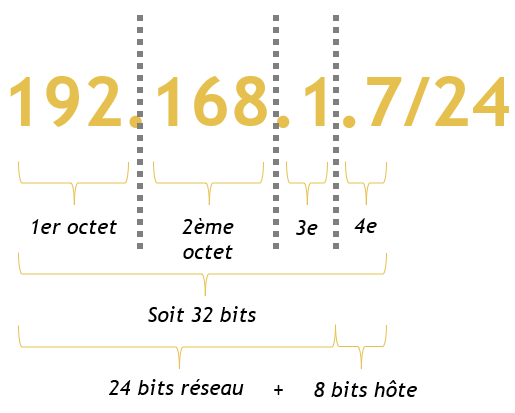
Nous avons l’adresse IP 192.168.1.7 avec un masque en notation CIDR de /24. Nous savons maintenant qu’une adresse IPv4 est codée sur 32 bits au total. Le /24 veut dire que sur ces 32 bits au total, 24 seulement représentent l’adresse du réseau entier que l’on va maintenant pouvoir trouver en partant de la gauche.
Cela signifie que « 192.168.1 » est la partie identifiant le réseau car les 3 premiers octets ensemble font 24 bits (rappel : 1 octet = 8 bits).
Il reste donc 1 octet complet (32-24 = 8 bits soit 1 octet) qui identifient la partie hôte. On peut donc dire que l’IP 192.168.1.7 est la 7ème IP disponible dans le réseau.
Désormais, on sait que la machine ayant cette adresse IP appartient au réseau 192.168.1.0 /24. Seul les bits représentant les hôtes vont changer à l’intérieur de ce réseau mais jamais l’adresse du réseau elle même. Par exemple un PC A aura l’IP 192.168.1.48 /24, un PC B aura l’IP 192.168.1.199 etc… jusqu’à la 192.168.1.254. Oui j’ai bien dit .254 MAX car l’adresse 192.168.1.255 est la dernière IP disponible dans le réseau et elle est dédiée au broadcast, elle ne peut donc jamais être utilisée.
Toutes les machines situées dans le réseau 192.168.1.0/24 pourront communiquer ensemble. Si vous avez une machine sur le réseau 192.168.2.0/24, elle est sur un réseau différent et ne pourra pas communiquer par défaut avec la 192.168.1.7/24 par exemple.
|
Pour aller plus loin : Pour découvrir plus de choses sur la construction d’une adresse IPv4 et la façon d’utiliser le masque pour calculer un nombre d’hôtes disponibles ou identifier l’adresse du réseau, je vous renvoie vers un précédent article : Calculer l’adresse IP d’un réseau et le nombre d’hôtes disponibles. |
Les adresses IP ne sont pas les seules informations nécessaires pour le fonctionnement d’un réseau. C’est là que les « protocoles » et les « ports logiciels » vont faire leur entrée ! Mais avant toutes choses, il faut déjà bien comprendre comment fonctionnent les principaux équipements réseau car on apprend à marcher avant de courir jeune padawan.
A. Zoom sur le switch

Résumé : Le switch (ou commutateur) permet de relier des machines entre elles dans un même réseau. C’est un équipement réseau intelligent doté de nombreux ports pour brancher des câbles Ethernet ou Fibre Optique et les raccorder à des machines. Un switch peut également avoir la fonction de routeur, on parle alors de switch de niveau 3 (car couche 3 OSI = réseau) et dans ce cas, il possède une adresse IP afin d’assurer le routage. Sinon, c’est un équipement dit de niveau 2 (car couche 2 OSI) qui n’a pas besoin d’adresse IP, sauf pour y accéder à distance pour l’administrer.
Le switch est l’équipement qui permet de relier entre elles toutes les machines d’un même réseau. Il permet aux différents éléments de communiquer entre eux sans sortir du réseau local.
Le switch est un équipement de couche 2 (liaison de données) du modèle OSI. Pour faire transiter les données, il analyse les adresses MAC (protocole Ethernet) des équipements source et destination indiquées dans l’entête de la trame (si vous avez eu un peu de mal avec cette phrase, retournez voir le chapitre concernant le modèle OSI).
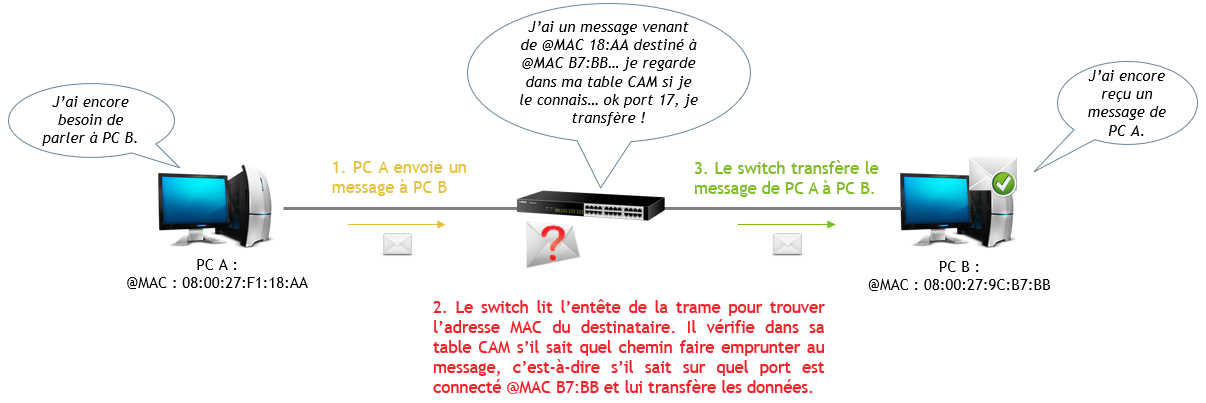
Voici un schéma simplifié d’un échange entre 2 ordinateurs d’un même réseau reliés l’un à l’autre par un switch :

NON, en réalité le switch connaît par défaut uniquement les adresses MAC des équipements qui lui sont reliés.
Lorsque des équipements reliés par un switch communiquent, le switch en profite pour conserver temporairement dans sa mémoire les adresses MAC. Il est alors capable de se souvenir que sur son port n°1 est branché un équipement qui a pour adresse MAC 08:00:27:F1:18:AA, et sur son port n°17, un autre équipement qui a pour adresse MAC 08:00:27:9C:B7:BB. Cette mémoire s’appelle une « table CAM » (Content-Addressable Memory). Il pourra ainsi transférer les messages plus vite si ces 2 là communiquent de nouveau dans les prochaines minutes. On parle de construction dynamique (automatique) de la table CAM.
|
Pour aller plus loin : Si vous vous amusez avec Cisco Packet Tracer comme recommandé un peu plus haut, vous pouvez saisir la commande suivante sur un switch Cisco pour voir la table CAM (via l’onglet « CLI » du switch) :
|
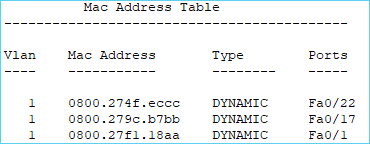
La table CAM ne conserve les adresses MAC des équipements connectés au switch que quelques minutes par défaut.
Lorsqu’il consulte sa table CAM, il se peut qu’elle soit incomplète si des équipements n’ont pas communiqué depuis un petit moment (le PC sur le port 17 a été éteint pour le week-end par exemple). Le switch ne sait donc pas sur quel port précis transférer le message pour arriver à destination. Dans ce cas là, il va tout simplement transférer le message sur TOUS ses ports actifs (sauf celui de la source) en espérant que ça arrive bien à l’adresse MAC de destination. Ceux qui ne sont pas destinataires vont simplement ignorer le message.
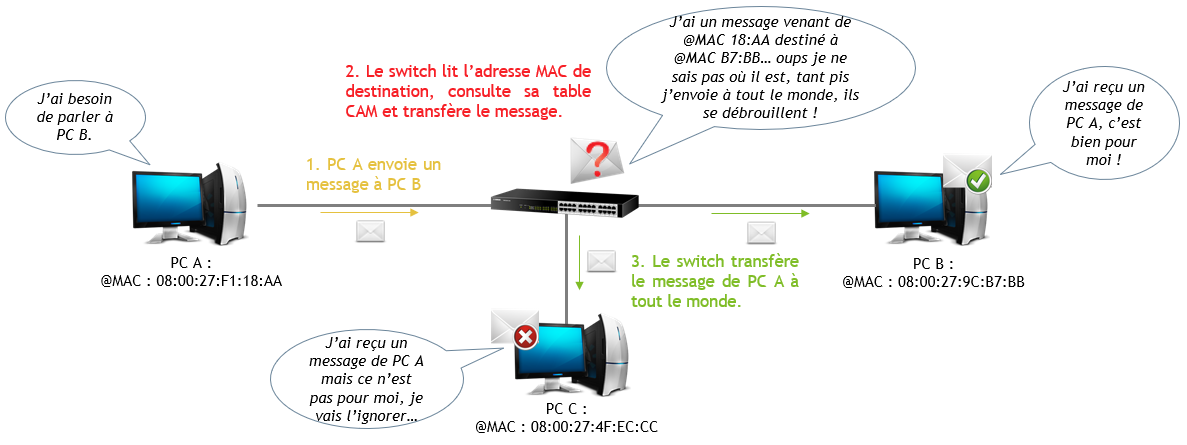
OK, faisons un petit récapitulatif du fonctionnement simplifié d’un switch étape par étape :
- Un PC A envoie un message à un PC B.
- Le message arrive sur le switch qui relie entre eux les deux PC.
- Le switch lit l’entête du message qui le concerne (donc la trame car le switch est un équipement de couche 2) et recherche l’adresse MAC source pour connaître l’expéditeur.
- Une fois l’adresse MAC source identifiée, il met à jour sa table CAM et note que sur tel port est associé cette adresse MAC.
- Le switch recherche dans l’entête de la trame l’adresse MAC de destination cette fois-ci pour connaître le destinataire.
- Il recherche dans sa table CAM une correspondance entre la MAC de destination et l’un de ses ports.
- Si une correspondance est trouvée, le switch envoie la trame uniquement sur le port où est située la MAC de destination. Si aucune correspondance n’est trouvée, le switch envoie la trame sur tous les ports, sauf celui de l’expéditeur.
- Si le destinataire se manifeste, le switch mettra à jour sa table CAM et notera que sur tel port est associé telle MAC. Les autres machines qui recevront le message et ne seront pas destinataire vont l’ignorer.
Vous vous dites peut être que si toutes les autres machines reçoivent le message, quelqu’un peut donc l’intercepter pour nuire… c’est vrai en effet mais ce n’est pas si simple que cela, vous voyez ici seulement le fonctionnement simplifié.
La table CAM d’un switch peut être construite de façon statique (manuel), c’est-à-dire que seules les adresses MAC autorisées par l’administrateur réseau peuvent se connecter sur tel ou tel port du switch.
Un même switch physique peut desservir plusieurs réseaux différents, on parle alors de VLAN, « Virtual Local Area Network », c’est-à-dire de réseaux virtuels locaux. C’est comme si on découpait le switch en plusieurs petits morceaux en disant par exemple que du ports 1 à 11 c’est un réseau, et du ports 12 à 24, c’est un autre réseau… etc
B. Zoom sur le routeur

Résumé : Le routeur permet de relier différents réseaux entre eux. Il peut être filaire ou wifi s’il est doté d’antennes (internes ou externes). C’est un équipement réseau intelligent de couche 3 du modèle OSI car il gère l’interconnexion de réseaux. Il est doté de quelques ports spécifiques reliés eux-mêmes à d’autres routeurs. Le routeur a également la fonction de switch mais uniquement pour quelques machines car il possède peu de ports en général.
Le routeur est l’équipement qui permet de relier entre eux différents réseaux. Il permet aux équipements de sortir de leur réseau local privé afin de communiquer avec d’autres réseaux locaux ou avec Internet, c’est une « passerelle » qui possède plusieurs adresses IP, une dans chaque réseau sur lequel il se trouve.
Le routeur est un équipement de couche 3 (réseau) du modèle OSI. Pour faire transiter les données, il analyse les adresses IP des équipements source et destination indiquées dans l’entête du paquet.
Voici un schéma simplifié d’un échange entre 2 machines sur 2 réseaux séparés, reliés l’un à l’autre par un routeur (entre chaque PC et le routeur, pensez bien qu’il y a un switch qui n’est pas ici représenté) :
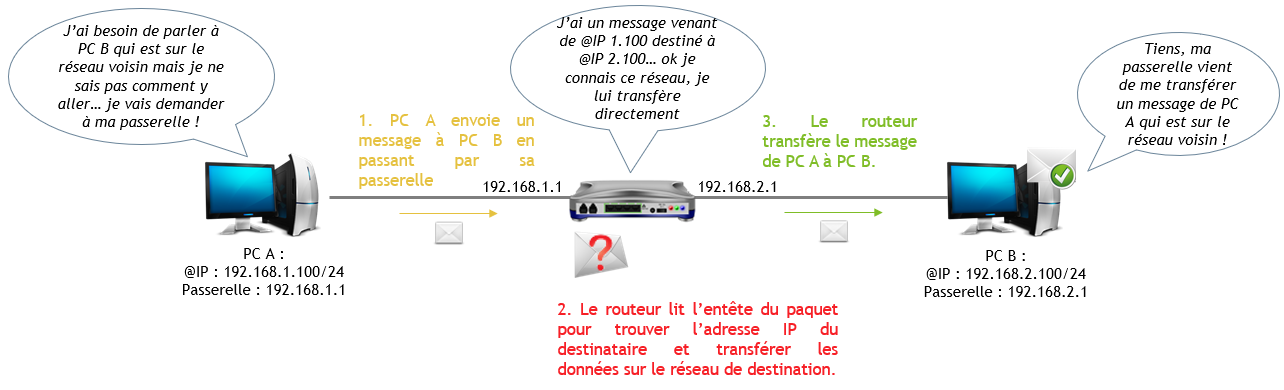
NON, en réalité le routeur connaît par défaut uniquement les adresses des réseaux sur lesquels il est directement connecté. On dit qu’il a « une patte » sur chaque réseau, c’est pour cela qu’il possède plusieurs adresses IP, une sur chaque réseau auquel il est connecté.
Lorsqu’il a besoin de transférer des données d’un réseau à un autre, il va faire appel à sa mémoire interne pour essayer de déterminer par quel chemin il devra faire passer le message pour l’envoyer sur le bon réseau de destination. Cette mémoire s’appelle une « table de routage ». Elle contient les « routes », les chemins, que le routeur devra faire emprunter aux paquets.
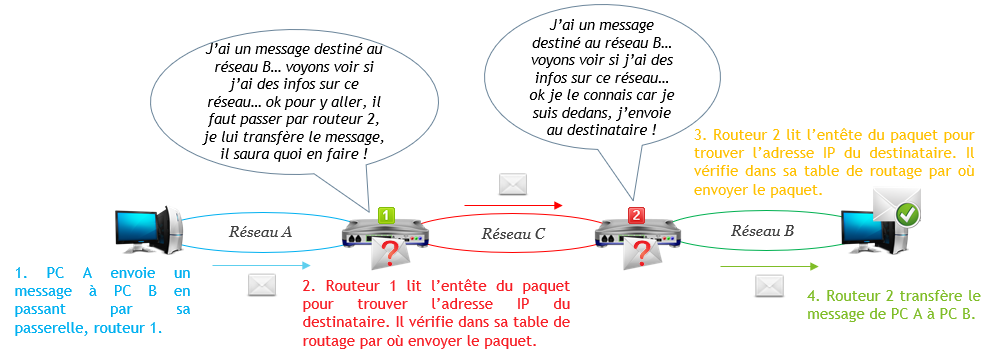
On parle de route mais en réalité, il s’agit de l’adresse IP d’un autre routeur susceptible de connaître le réseau de destination auquel sera envoyé le message. Le 1er routeur se décharge en quelques sortes sur un collègue routeur. Une liaison entre deux routeurs forment un réseau à part entière.
|
Pour aller plus loin : Si vous vous amusez avec Cisco Packet Tracer comme recommandé un peu plus haut, vous pouvez saisir la commande suivante sur un routeur pour voir la table de routage (via l’onglet « CLI ») :
Pour en découvrir plus sur le routage, notamment le routage dit « statique », consultez cet article : Introduction au routage IP |
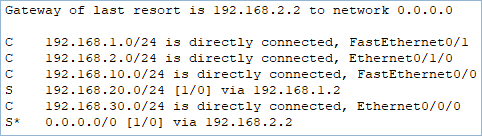
La table de routage peut avoir des routes dites « statiques », c’est-à-dire renseignées par l’administrateur réseau qui va textuellement dire au routeur : « Si tu as besoin de parler au réseau 192.168.1.0 qui a pour masque 255.255.255.0, transfère le message au routeur voisin qui a pour IP 192.168.254.1, il se chargera de remettre le message pour toi ». Il existe également des protocoles de routage statique permettant de simplifier la tâche de l’administrateur en ne rentrant pas toutes les routes une à une. La table de routage peut aussi être « dynamique » grâce à des protocoles spécifiques aux routeurs qui vont savoir s’échanger eux-mêmes les routes qu’ils connaissent. La table de routage se construit alors de façon automatique.
|
Pour aller plus loin : Pour découvrir le routage dynamique, consulter cet article : Introduction au routage IP dynamique |
Le collègue routeur est obligatoirement un voisin auquel le 1er routeur est connecté directement, ils sont tous les deux sur le même réseau sinon le transfert de données n’est pas possible. Le second routeur devient alors une « passerelle » du 1er routeur et ainsi de suite pour couvrir le monde entier. A chaque fois qu’un message passe par un routeur, on dit qu’il fait un « saut ».
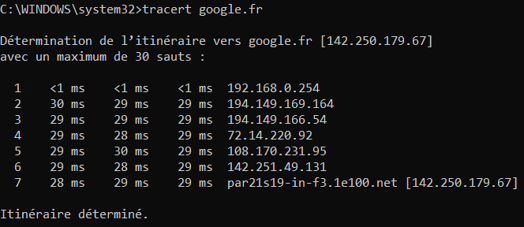
On peut voir le nombre de sauts réalisés entre votre PC et un serveur de Google par exemple en utilisant l’outil « traceroute » en ligne de commande.
Un routeur doit également posséder une « gateway of last resort », soit une passerelle de dernier recours, qui n’est autre, une fois encore, qu’un routeur voisin, vers lequel il redirigera tous les paquets lorsqu’il n’a aucune autre indication sur la route à suivre dans sa table de routage. Cette passerelle représente la « route par défaut » qui se matérialise en informatique par le réseau 0.0.0.0 et le masque 0.0.0.0 (le fameux 0.0.0.0 :-D).
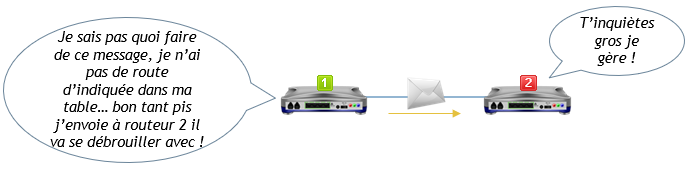
Dac, petit récapitulatif du fonctionnement d’un routeur dans un réseau :
- Un PC A sur un réseau A envoie un message à un PC B sur un réseau B.
- Le message parti de PC A arrive sur le routeur A (c’est donc sa passerelle).
- Le routeur lit l’entête du message (le paquet) et recherche l’adresse IP source pour connaître l’expéditeur.
- Le routeur recherche dans l’entête du paquet l’adresse IP de destination pour identifier sur quel réseau elle se trouve et voit que c’est pour réseau B.
- Il recherche dans sa table de routage s’il a une indication concernant le réseau de destination. A partir de là, plusieurs possibilités :
- Si le routeur est directement connecté sur le réseau de destination, il transfère directement le message à l’intéressé.
- Si le routeur n’est pas connecté au réseau de destination, il recherche dans sa table de routage la route à prendre pour s’y rendre, c’est-à-dire quelle est l’adresse IP du prochain routeur qui sait aller sur le réseau de destination et il transfère le fameux message à son collègue routeur qui lui-même va reproduire les mêmes étapes.
- Si le routeur n’est pas connecté au réseau de destination et qu’aucune route ne lui précise comment aller sur le réseau de destination, il va transférer le message sur sa route par défaut, c’est-à-dire à un collègue routeur qui pourrait peut être savoir quoi faire du message par la suite. En résumé, il se décharge de sa responsabilité.
- Si le routeur n’est pas connecté au réseau de destination, qu’aucune route ne lui précise comme s’y rendre et qu’aucune route par défaut n’est renseignée, le routeur abandonne purement et simplement le paquet.
Vous avez vu dans les deux dernières parties l’existence de la table CAM et la table de routage. Sachez qu’il existe également une « table ARP » (Address Resolution Protocol) qui fait le lien entre une adresse IP et une adresse MAC. ARP est un protocole de couche 3 du modèle OSI. Il émet des requêtes sur le réseau afin d’obtenir l’adresse MAC des équipements et ainsi leur permettre de communiquer en liant leur @MAC à @IP.
|
Pour aller plus loin : Pour voir la table ARP d’un routeur sur Cisco Packet Tracer, saisissez (toujours dans l’onglet « CLI » du routeur) la commande suivante :
Et pour en savoir plus sur la table ARP, vous pouvez regarder ce lien : Présentation de la table ARP |

C. Zoom sur le hub

Résumé : J’ai brièvement évoqué cet équipement en début d’article et peut être que vous en avez déjà entendu parlé donc nous allons juste faire un petit arrêt dessus pour bien le distinguer du switch. Le hub (ou concentrateur) permet de relier des machines entre elles dans un même réseau, exactement comme un switch. Par abus de langage, on l’appelle souvent « mini-switch ». C’est un équipement doté de quelques ports afin de raccorder plusieurs machines. Contrairement au switch, le hub n’est pas un équipement dit intelligent, il ne gère pas le flux de données, on dit qu’il est « passif ». Il se contente de transférer des données, exactement comme un câble. C’est donc un équipement de couche 1 du modèle OSI.
Le hub est, tout comme le switch, un équipement permettant de relier entres elles des machines d’un même réseau. La différence entre hub et switch est simple : le switch est dit « intelligent » car il sait gérer le flux de données (grâce aux adresses MAC). Le hub ne sait pas faire cela, on dit qu’il est « passif ». En réseau, c’est clairement une « multiprise » qui, tout comme un simple câble, transporte des données.
Le hub est donc un simple support, c’est un équipement de couche 1 (physique) du modèle OSI. Quand il reçoit des données, il se contente de les renvoyer sur l’ensemble de ses ports sans chercher à savoir quoi que ce soit.
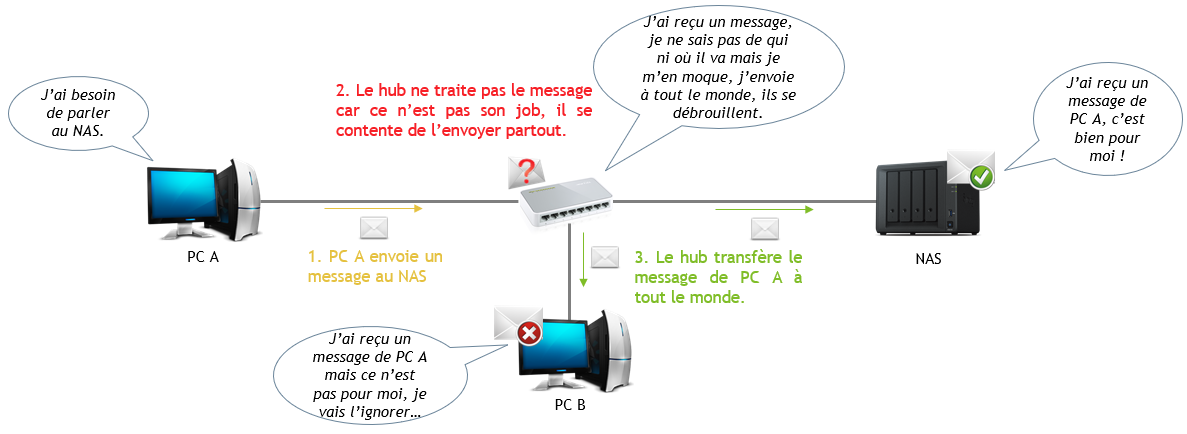
Le hub envoyant à tout le monde n’est pas très sécurisé, il est rare en entreprise et même au grand public au profit du switch. Il y a peu de chance que vous en croisiez un (j’espère en tout cas…) mais au moins vous savez ce que c’est.
D. Zoom sur la borne wifi

Résumé : La borne wifi, ou point d’accès wifi, permet d’accéder au réseau en utilisant la technologie sans fil. C’est un équipement réseau intelligent pouvant être placé n’importe où sur le réseau et devant être relié à un switch ou un routeur afin de diffuser le signal du réseau en wifi. Une borne sans fil qui transforme simplement un signal filaire en onde wifi est vue comme un switch (couche 2). Si le réseau wifi est différent du réseau filaire, elle devient alors un routeur (couche 3).
Exactement de la même façon que le reste à la différence qu’une borne wifi utilise des ondes invisibles pour accéder au réseau plutôt que des câbles. Elle peut aussi être utile pour élargir la zone de couverture wifi.
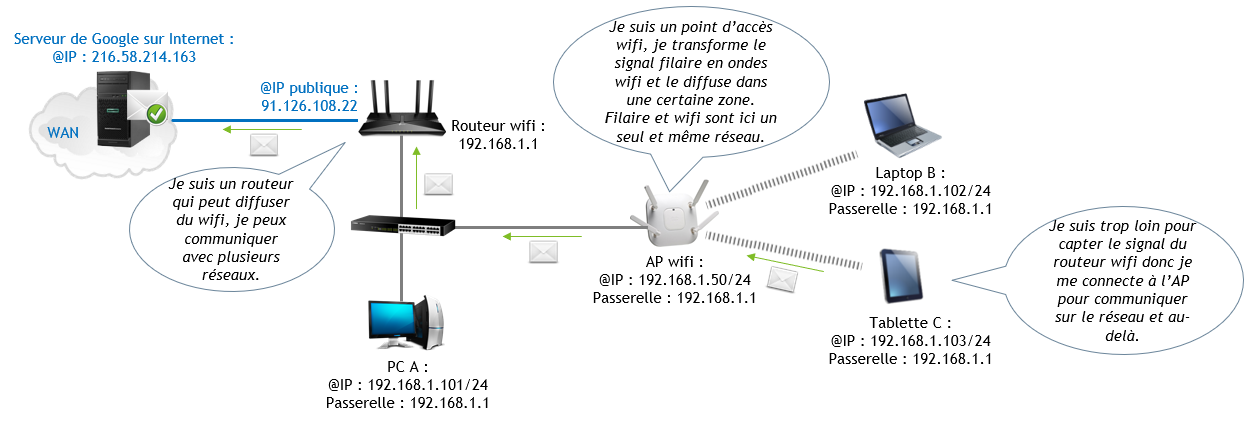
La borne wifi, ou le point d’accès wifi (AP pour Access Point), est un équipement qui permet de se connecter à un réseau sans fil. Elle possède des antennes (visibles ou pas), qui diffusent le signal du réseau. Elle peut servir de switch si elle sert à relier des équipements en wifi à un même réseau (couche 2 d’OSI), ou de routeur si le réseau wifi est différent du réseau filaire (couche 3 d’OSI). Un routeur peut également être diffuseur du signal wifi (comme la box internet) en revanche un point d’accès wifi n’est pas forcément un routeur, parfois c’est juste un diffuseur du signal.
|
Pour aller plus loin : Pour en apprendre plus sur le wifi, c’est par ici : Introduction au Wi-Fi |
Tout comme un switch que l’on veut administrer, elle peut disposer d’une adresse IP pour y accéder à distance.
E. Zoom sur le serveur

Résumé : Le serveur est un ordinateur mais en beaucoup plus puissant. Il peut accueillir une grande quantité de composants (plusieurs processeurs, alimentations, cartes réseaux, disques ou encore des dizaines de barrettes de RAM…). Son rôle est de fournir des services utilisables en réseau. Ces services sont accessibles selon les protocoles et les ports qu’il faudra utiliser pour les joindre. Un serveur possède son propre système d’exploitation, plus allégé qu’un ordinateur client, mais un simple ordinateur peut aussi être un serveur s’il fournit lui-même des services en réseau. Il fournit un service, on peut dire un accès à une application par exemple, c’est donc un équipement de couche 7 du modèle OSI, au même titre qu’un ordinateur utilise un service ou une application.
Le serveur est l’équipement qui offre des services qui seront utilisables en réseau. Par exemples, un site web est hébergé sur un serveur, les mails transitent grâce à des serveurs, des fichiers sont stockés sur des serveurs, l’authentification se fait via un serveur, etc… Une machine « cliente », est celle qui utilise les services fournis par un serveur.
Pour utiliser ces services, un poste client (un ordinateur par exemple), va émettre des « requêtes » à destination d’un serveur. Le serveur lui va émettre des « réponses » à destination du poste client. Le serveur attend donc patiemment que l’on vienne lui demander quelque chose. Il utilise pour cela ce qu’on appelle des « ports d’écoute ».
Pour pouvoir communiquer avec un service précis, les machines clientes vont devoir préciser le service qu’ils veulent atteindre. Cela se fait en utilisant le protocole du service mais aussi le port qui lui est associé, on parle alors de « port logiciel ». Il existe 65536 ports (le zéro étant inclut, oui oui vous avez bien lu !) dont certains sont normés, c’est-à-dire appliqués d’office à un service bien défini et qu’on ne peut donc pas utiliser comme on le souhaite (par exemple, le protocole le plus célèbre est celui du web, le « HTTP », dont le port associé est le port 80). Ce port réseau est lui-même associé avec un protocole de transport pour que le message soit acheminé (aller/retour), en général soit TCP, soit UDP (couche 4 OSI)
Pour émettre une requête auprès d’un serveur, le poste client va donc utiliser plusieurs informations :
- Le protocole à utiliser selon le service ciblé car chaque service possède son propre protocole (web, mail…)
- Le port utilisé par ce protocole, toujours selon le service utilisé
- Le protocole de transport utilisé par le protocole du service (TCP ou UDP)
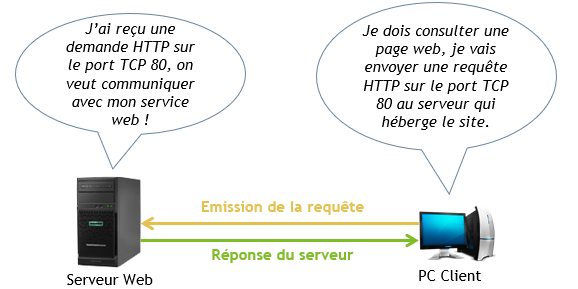
Un serveur peut délivrer plusieurs services différents, il est donc important d’utiliser les protocoles et les ports réseaux associés au service ciblé.
Bien évidemment non ! Ce n’est pas vous personnellement qui précisez le port et le protocole (sauf dans certains cas spécifiques), les machines savent bien gérer cela entre elles et utilisent les ports réseaux « par défaut ». Quand votre navigateur Internet va sur www.google.fr, il sait de lui-même qu’il fait du HTTP ou HTTPS et émet une requête à l’adresse IP du serveur web de Google, qui s’écrit comme ceci : 216.58.214.163:80, c’est-à-dire @IP_destination + : + port du service visé.
Le serveur lui est en écoute sur ce port, il attend. C’est ainsi qu’il va pouvoir recevoir les requêtes des clients et y répondre. Il saura alors que tel client à besoin de tel service et pas d’un autre. Les ports par défaut sont souvent modifiés par soucis de sécurité.
Voici quelques exemples d’associations de port par défaut/service (tous de couche 7 du modèle OSI) et leur mode de transport (couche 4) :
| Service | Rôle | Port par défaut | Protocole de transport |
| HTTP / HTTPS | Consultation de site web via un navigateur (non sécurisé/sécurisé) | 80 / 443 | TCP |
| IMAP / IMAPS | Accès aux mails qui restent hébergés sur un serveur (non sécurisé/sécurisé) | 143 / 993 | TCP |
| POP3 / POP3S | Récupération des mails en local (non sécurisé/sécurisé) | 110 / 995 | TCP |
| SMTP / SMTPS | Envoi de mails (non sécurisé/sécurisé, le port dépend du mode d’authentification) | 25 / 465 ou 587 | TCP |
| SNMP | Gestion d’équipements réseau (supervision, diagnostique, information…) | 161 et 162 | UDP |
| LDAP / LDAPS | Accès aux services d’annuaire tel qu’Active Directory (non sécurisé/sécurisé) | 389 / 636 | TCP |
| DNS | Résolution de noms de domaine en adresses IP | 53 | UDP |
| DHCP | Attribution automatique de configuration réseau (IP, masque, passerelle…) | 67 (serveur) et 68 (client) | UDP |
| FTP / SFTP | Transfert de fichiers (non sécurisé/sécurisé) | 21 (serveur) et 20 (données) / 22 | TCP |
| SSH | Etablissement d’une connexion distante sécurisée | 22 | TCP |
| VNC | Prise de main pour visualisation et contrôle d’une machine distante | 5900 | TCP |
| NTP | Synchronisation horaire à une même source de machines en réseau | 123 | UDP |
| SIP /SIPS | Etablissement d’une communication multimédia (notamment en VoIP) | 5060 / 5061 | UDP |
|
Pour aller plus loin : Pour consultez la liste de tous les ports, je vous mets ici deux ressources : LISTE DES PORTS TCP UDP et Liste de ports logiciels |
En entreprise, l’accès à certains ports est fermé par sécurité. Il faut les autoriser dans le firewall pour que la communication avec le service fonctionne. De façon plus générale, il est préférable d’utiliser les protocoles dans leur version sécurisée.
6. Vue globale d’un échange
Vous l’aurez compris, un simple clic sur le net entraine derrière une grosse logistique finalement et tout se passe bien sur à la vitesse de la lumière.
Bien sûr ! Prenons un échange simple comme par exemple un PC qui veut surfer sur le web en passant par Google :

|
Info + : Dans cet exemple je reste sur du HTTP 80 pour ne pas complexifier les choses mais dans la réalité, ça sera plutôt du HTTPS 443. |
Si on prend un peu de recul, on peut même visualiser les couches du modèle OSI qui sont toutes descendues quand le PC émet la requête.
Elles sont remontées et redescendues à chaque équipement réseau croisé (seules les couches utilisées par l’équipement), et elles sont toutes remontées une fois le message arrivé au serveur.
Puis ensuite le message fait tout simplement le chemin inverse pour apporter la réponse : Service web protocole HTTP port 80 (7), Langage HTML (6), session établie entre les 2 (5), transport TCP (4), adresse IP destination (3), adresse MAC destination (2), câblage (1) et départ puis remontée vers le client.
Oui car souvenez vous que pour communiquer dans un réseau, ce sont les adresses IP qui sont utilisées !
Derrière chaque machine, que ce soit un serveur web, un serveur de messagerie, votre PC, votre box ou tout autre matériel, se cache un nom. Ce nom est associé à l’adresse IP de l’équipement pour une raison simple : nous ne sommes pas capable de retenir les adresses IP du monde entier… alors que facebook.com ou google.fr, ça notre cerveau sait le retenir ou au pire, il sait comment trouver l’information facilement.
Pour être capable d’établir une correspondance entre un nom et une adresse IP, votre machine va faire appel à un service nommé le « DNS » (Domain Name System). Sans DNS, votre PC pourra aller sur le net en tant que machine, mais pas vous en tant qu’Homme !
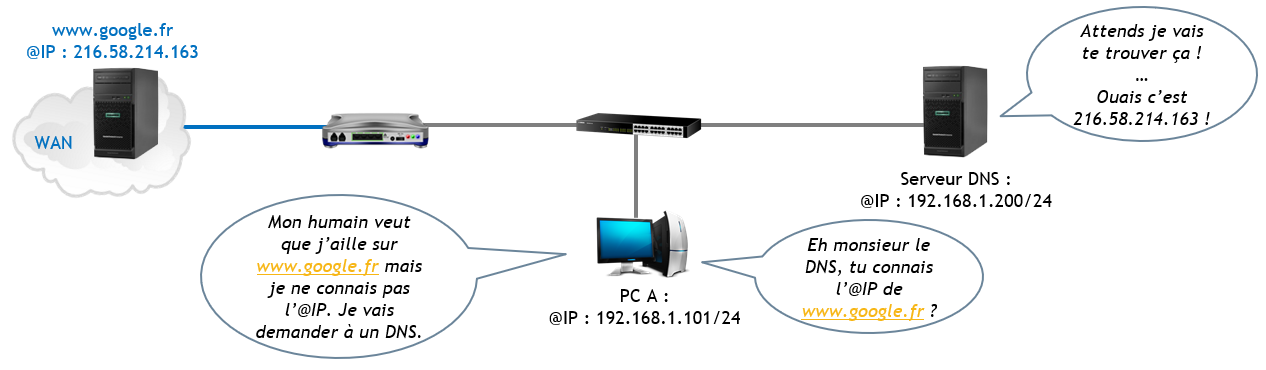
C’est un service essentiel. Votre box internet à la maison est un serveur DNS. Vous pouvez aussi utiliser des DNS publics comme par exemples ceux de Google (8.8.8.8 ou 8.8.8.4) ou CloudFlare (1.1.1.1).
Pour répondre aux demandes, notamment de noms sur Internet, un serveur DNS fait appel à d’autres collègues serveurs DNS afin d’avoir la réponse complète. Aucun DNS ne connait tous les noms de domaine qui existent dans le monde.
|
Pour aller plus loin : Pour en apprendre plus sur le service DNS et son fonctionnement, consultez les articles suivants : Introduction au DNS [1/2] : Le principe des noms de domaine et Introduction au DNS [2/2] : Le fonctionnement du service DNS |
Parfait c’est le but recherché ! Pas vraiment une nouvelle info mais plutôt un mini récap sur un point précis…
Pour communiquer à l’intérieur d’un réseau, un ordinateur a besoin obligatoirement de 2 choses :
- Une adresse IP dans le réseau
- Un masque de sous-réseau qui permet de l’identifier au sein de ce réseau
Pour communiquer avec le monde extérieur, un autre réseau comme par exemple internet, il a EN + besoin de 2 autres choses :
- Une adresse de passerelle, qui est toujours l’IP d’un routeur (ou un switch qui fait routeur, ou une borne wifi qui fait routeur, bref un routeur !)
- Une adresse de DNS pour résoudre les noms de domaine en adresse IP.
Sans ces éléments, votre machine n’ira pas bien loin.
N’oubliez pas pour autant que vous n’avez vu ici que les bases, le monde du réseau informatique est très très vaste, à vous de creuser le sujet maintenant.
Je vous conseille le site frameip.com qui est une excellente ressources sur laquelle vous trouverez une quantité énorme d’infos détaillées (entêtes, IPv6, modèle TCP/IP, protocoles, VPN, NAT, VOIP…).
Vous pouvez utiliser l’outil Cisco Packet Tracer pour simuler certains comportements dans un réseau, mieux visualiser ce qu’il se passe et vous faire la main surtout avec les switchs et routeurs. Le logiciel Wireshark également peut être intéressant, c’est un analyseur de réseaux. Il nous montre le trafic qui circule au sein d’un réseau, le contenu des trames et des paquets, il permet aussi parfois de se dépanner quand on butte sur un problème épineux…
Ceci met fin à cette introduction au réseau informatique, en espérant que vous avez pris autant de plaisir à la lire que moi à l’écrire (ouais en fait nen on va pas se mentir, c’est un sujet chiant…) 
See U 


