

Ce qui fait aujourd’hui qu’on arrive à transmettre des paquets de données d’un réseau A vers un réseau B c’est ce qu’on appelle le routage IP.
Le routage s’appuie sur des protocoles pour mener à bien sa mission. Mais quels sont ces protocoles et comment s’y prennent-ils pour faire transiter nos données ?
Et bien c’est ce qu’on va voir grâce à ce 2nd article qui va vous donner un 1er aperçu de ce qu’est le routage dynamique… 
Initiation au routage IP et mise en place du routage dynamique
Allez un petit rappel rapide avant cette première initiation au routage dynamique (d’ailleurs j’espère que vous êtes bien accroché parce que ça sera moins drôle que le statique) ! 
|
Info ++ : J’insiste sur le terme « initiation » car tous les sujets concernant un protocole de routage ou autre ne seront pas traités, il y a beaucoup trop à dire et ce n’est pas le but de cet article qui doit rester une « découverte » des protocoles de routage dynamique. |
Le routage est un mécanisme grâce auquel le meilleur chemin sera sélectionné pour acheminer des données informatiques à travers les réseaux.
Le routage IP intervient au niveau de la couche 3 Réseau du modèle OSI (couche Internet du modèle TCP/IP).
L’équipement dédié à l’envoi de paquets à travers un réseau de données est le routeur. Il a pour rôle d’interconnecter les réseaux entre eux en sélectionnant le meilleur chemin, la meilleure route à suivre, pour qu’un paquet arrive à sa destination finale.

Pour que les routeurs puissent transférer des paquets d’un réseau à un autre, il faut leur indiquer des chemins vers des destinations diverses, qu’ils vont consigner dans leur table de routage.
Dans l’article précédent, j’ai également évoqué la notion de distance administrative. Plus celle-ci est basse, plus la route sera considérée comme « fiable ». La route la plus fiable sera donc celle empruntée en priorité par le routeur pour acheminer les paquets.
Si dans un réseau vous utilisez plusieurs protocoles de routage sur vos équipements, la distance administrative du protocole qui sera la plus basse, gagnera.
|
Info + : Si vous ne possédez aucune connaissance en routage, je vous conseille de lire l’article précédent avant d’aborder celui-ci. Le 1er post est disponible au lien suivant : Introduction au routage IP statique |
Dans cet article, nous allons voir et implémenter 3 protocoles de routage dynamique : RIP, EIGRP et OSPF.
Les protocoles de routage dynamique vont mettre à jour automatiquement les tables de routage des routeurs (entre autres), contrairement au routage statique qui nécessite que l’administrateur renseigne lui-même les routes.
Avant d’aller plus loin, il faut que vous ayez quelques infos supplémentaires. 😉
Vous entendrez parler de protocoles de routage à « état de lien » ou à « vecteur de distance ».
La différence réside dans les algorithmes de routage utilisés qui vont gérer la façon dont les informations sur les réseaux seront transmises entre les routeurs.
Protocole de routage à vecteur de distance
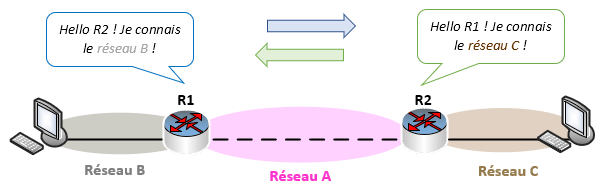
Un protocole dynamique à vecteur de distance va s’appuyer sur les distances entre les différents nœuds d’un réseau, c’est-à-dire le nombre de sauts qui permet d’atteindre les autres routeurs.
Un routeur qui utilise un protocole à vecteur de distance va transmettre périodiquement à tous les routeurs avec lesquels il peut communiquer, les routes dont il dispose dans sa table de routage.
|
Info + : Un protocole de routage dynamique à vecteur de distance utilise l’algorithme de Ford-Bellman. |
La diffusion des routes est annoncée uniquement aux routeurs proches. Ce veut dire qu’au final, les routeurs utilisant un protocole de ce type n’auront jamais la vision complète d’un réseau.
Le problème de ce type de routage est l’apparition de boucles. Les informations de routage étant échangées de façon périodique entre les routeurs (on parle de « convergence lente »), si une route s’effondre, est modifiée, ajoutée ou autres, les autres routeurs ne seront pas avertis de suite. Des paquets peuvent donc se retrouver à passer indéfiniment par les mêmes nœuds du réseau.
De façon plus globale, on peut dire qu’un protocole à vecteur de distance nécessite plus de bande passante, converge plus lentement et est simple à mettre en place. Il sera plutôt utilisé pour des petits réseaux.
Protocole de routage à état de liens
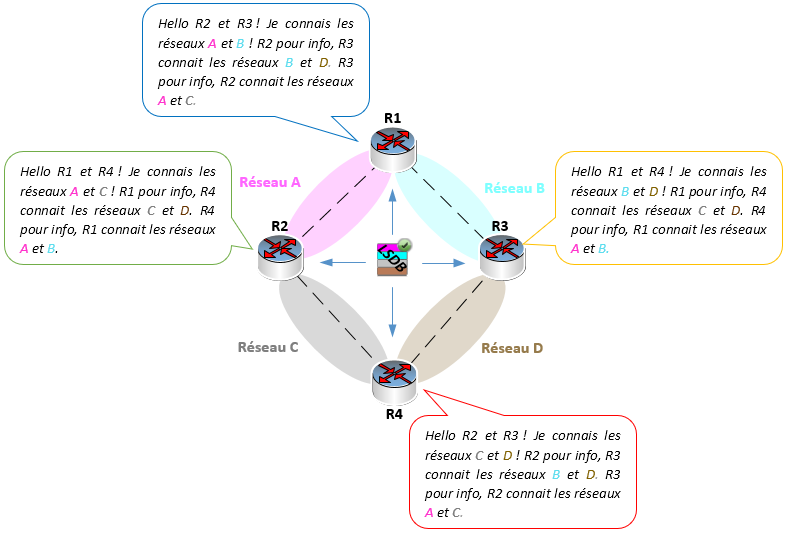
A la différence d’un protocole de routage à vecteur de distance, un protocole à état de lien permet à un ensemble de routeurs d’avoir la vision complète du réseau.
Dans ce type de protocole, les routeurs vont établir une relation de voisinage entre eux en envoyant des messages (de type « hello ») aux routeurs adjacents.
Une fois cette relation établie, ils vont synchroniser l’ensemble des informations sur l’intégralité du réseau (les messages contenant des infos sur le réseau sont appelés ici des LSA pour Link State Advertisements) pour construire leur base de données à état de lien commune (on parle de LSDB pour Link State Database).
Dans ce contexte, chaque routeur va transmettre à ses voisins toutes les informations qu’il possède ce qui fait que chaque routeur va finalement connaître la totalité du réseau et va pouvoir situer même les routeurs qui ne lui sont pas adjacents.
|
Info + : Un protocole de routage dynamique à état de lien utilise l’algorithme de Dijkstra. |
Avec un protocole de routage à état de lien, une mise à jour de la LSDB des routeurs sera effectuée directement lorsqu’une modification apparaît sur l’un des équipements.
Cela permet à tous les routeurs de détecter et/ou d’être alerté très vite lorsqu’une défaillance se produit sur un réseau grâce à leur relation de voisinage. On parle alors de convergence rapide.
Les informations des LSDB font donc l’objet d’une nouvelle analyse afin de déterminer un autre chemin pour aller d’un nœud à un autre dans le cas où la liaison initiale ne fonctionne plus.
En résumé, un protocole de routage à état de lien permet aux routeurs d’avoir une vision complète du réseau ce qui évite les potentiels problèmes de boucle. C’est un protocole évolutif utilisant une conception hiérarchique utilisée pour des grands réseaux.
Bien maintenant que vous savez tout cela, je vous propose de passer à la pratique !
Implémentation du routage dynamique
Nous allons reprendre la même topologie que dans l’article précédent car elle est simple pour un premier aperçu. A vous par la suite d’ajouter plus de réseaux et donc plus de routeurs, de couper des liens entres eux, de voir comment se mettent à jour les échanges etc…
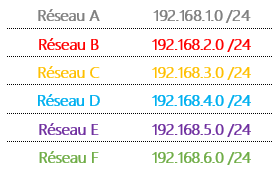
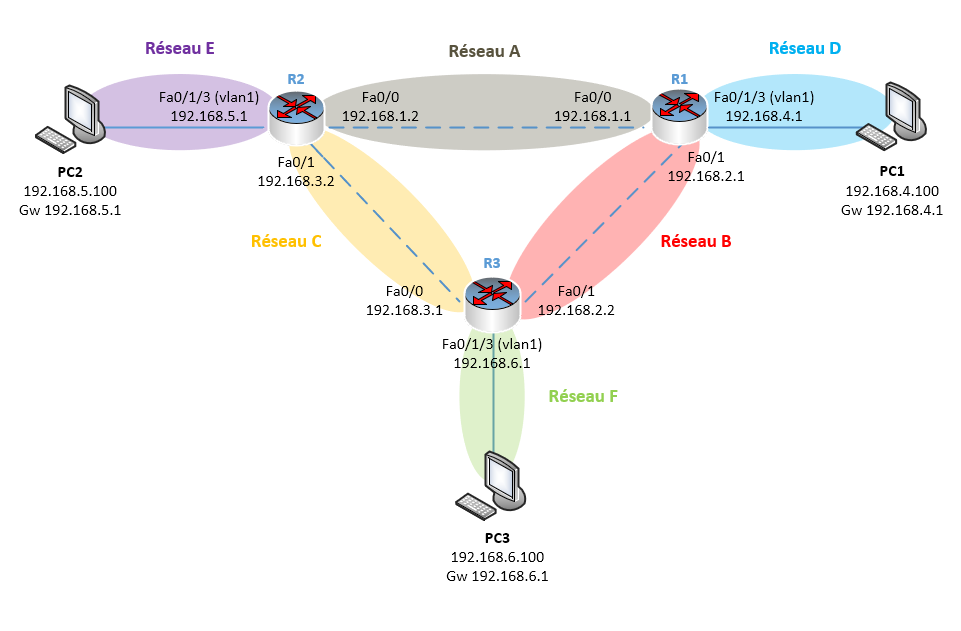 Nous avons dans cette topologie 6 réseaux :
Nous avons dans cette topologie 6 réseaux :
Notre but ici sera que toutes les machines qui sont sur des réseaux différents puissent communiquer.
Pour réaliser cette topologie sous Cisco Packet Tracer, j’ai dû ajouter des ports réseaux supplémentaires aux routeurs qui par défaut n’en possède que deux.
J’ai choisi de mettre des ports de switch (illustration de gauche) mais vous pouvez tout à fait ajouter un seul port Ethernet (illustration de droite) et lui attribuer directement une adresse IP.
![]()
|
Info ++ : : On ne peut pas attribuer d’adresse IP à des interfaces de switch. Il faut attribuer une adresse au VLAN n° 1 (réseau local virtuel), où toutes les interfaces sont incluses par défaut. |
Vous pouvez maintenant créer la topologie que l’on va utiliser sous Cisco Packet Tracer. Si besoin, vous verrez dans les 2 premières parties de la vidéo ci-dessous, comment j’ai créé l’infrastructure.
Assurez-vous bien que vos PCs pinguent leur passerelle respective avant d’aller plus loin.
|
Info + : N’oubliez pas de faire une copie du fichier Packet Tracer une fois votre infra de base prête (sans routage) pour pouvoir tester les différents protocoles de routage en repartant sur une infrastructure propre. |
Une fois prêt, vous pouvez passer à la mise en application du routage IP dynamique !
1. Le protocole RIP
Commençons par le plus simple, le protocole RIP (Routing Information Protocol) que nous utiliserons en version 2.
Le protocole RIP est un protocole de routage à vecteur de distance qui permet à un routeur de communiquer à ses voisins adjacents la métrique (distance maximale en termes de « sauts » séparant d’un réseau) qui le sépare d’un réseau x ou y.
Il se base uniquement sur le nombre de sauts séparant 2 réseaux et ne tient pas compte de l’engorgement du réseau ou de la vitesse de communication d’un lien, il utilisera simplement la route la plus courte.
|
Info + : Pour une route utilisant le protocole RIP, la distance administrative sera de 120. |
Des routeurs utilisant le RIP transmettront la totalité de leur table de routage à leurs voisins toutes les 30 secondes.
Il faut savoir que le RIP limite le nombre de saut à 15 pour éviter de créer des boucles. Au-delà de 15 sauts, un paquet sera abandonné. Pour cela, ce protocole convient au réseau comprenant moins de 15 routeurs.
La mise en place du RIP est assez simple à mettre en œuvre. Il suffit de déclarer dans un routeur seulement les adresses des réseaux qu’il forme avec d’autres routeurs.
Je m’explique : sur notre schéma topologique, regardons seulement nos réseaux de routeurs :

Nous voyons que :
- R1 forme un réseau (A) avec R2 et un réseau (B) avec R3
- R2 forme un réseau (A) avec R1 et un réseau (C) avec R3
- R3 forme un réseau (B) avec R1 et un réseau (C) avec R2
Quand nous allons mettre en place le routage RIP sur l’un de nos routeurs, il faudra donc lui déclarer ces réseaux.
Commençons par le routeur R1 ! Activez le routage RIP en version 2 avec les commandes suivantes en mode de configuration (commandes « en » et « conf t » préalables) :
router ripversion 2 |
Maintenant, nous aller déclarer les réseaux que R1 forme avec R2 et R3. La commande a la forme suivante :
network [ip_réseau]
Pour R1, vous pouvez donc saisir les 2 commandes suivantes :
network 192.168.1.0network 192.168.2.0 |
Vous devriez vous demander « et pourquoi on ne déclare pas aussi le réseau D vu qu’il est aussi connecté au routeur ? » 
Très bonne question merci de l’avoir posée !
En effet, actuellement, le réseau D n’est pas accessible. Vous pouvez tout à fait le déclarer comme les 2 autres en réalité, cela va fonctionner !
L’idée, c’est d’imaginer que le R1 est connecté à 2, 5, 12 autres réseaux… Cela signifie que je vais devoir rentrer la commande « network….. » pour chaque réseau ! Et comme je suis une bonne informaticienne, j’ai grave la flemme…
Du coup, on va rajouter un paramétrage supplémentaire au protocole RIP qui va permettre à mon routeur R1 de redistribuer à ses voisins, la liste de tous les réseaux qui lui sont connectés, sans avoir besoin de les déclarer un par un !
La commande à saisir pour ceci est la suivante :
redistribute connected |
Voilà, désormais mon routeur R1 est officiellement configuré pour faire du routage RIPv2 !
Maintenant, on s’attaque à R2 ! Voici les commandes à saisir pour le configurer :
router ripversion 2network 192.168.1.0network 192.168.3.0redistribute connected |
R2, ça s’est fait ! Pour R3, je vous laisse faire seul ! 😉
Une fois vos 3 routeurs configurés, lancez des tests de ping depuis les PC dans toutes les directions pour vérifier que tout le monde communique bien. Vous pouvez également utiliser la commande tracert pour voir par quel nœud (routeur) passe vos paquets.
|
Info + : La 4ème partie de la vidéo (dispo ICI) montre la configuration du routage RIP qui vient d’être effectuée. |
Pour visualiser la table de routage de R1, utiliser la commande suivante :
show ip route |
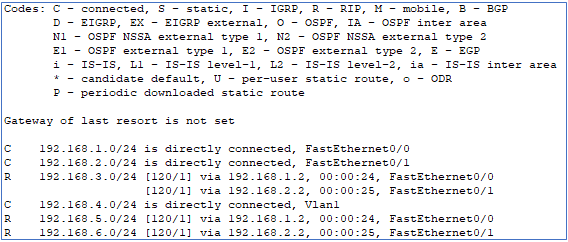
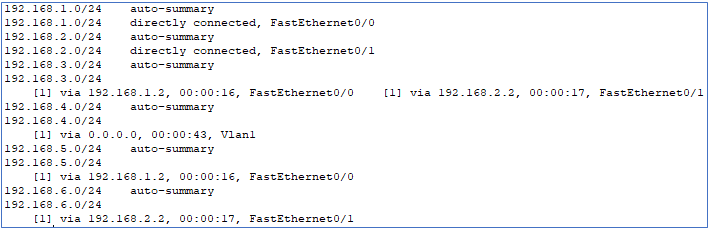
Et pour visualiser la base de données du protocole RIP, voici la commande :
show ip rip database |
2. Le protocole OSPF
Nous allons maintenant voir un protocole standard ouvert à état de liens appelé OSPF (Open Shortest Path First).
Avec le protocole OSPF, chaque routeur établit des relations de voisinage en envoyant régulièrement des messages de type « hello » dans une zone spécifique appelé système autonome.
Un système autonome c’est justement un ensemble de réseaux qui seront gérés par des groupes de routeurs qui s’échangent des informations en utilisant le même protocole de routage.
Chaque routeur de la zone qui répond va alors transférer la liste des réseaux auxquels il est connecté (message LSA) qui seront propagés de routeur à routeur pour former au final la base de données à état de liens (LSDB). L’algorithme du protocole sera ensuite en charge de déterminer la meilleure route à emprunter pour rejoindre chacun des réseaux inscrits dans la LSDB.
Après avoir recueilli toutes les informations, le routeur connaîtra alors l’ensemble de la topologie du réseau.
|
Info + : Pour une route utilisant le protocole OSPF, la distance administrative sera de 110. |
Contrairement au RIP, OSPF ne se base pas sur le nombre de saut pour déterminer la meilleure route à suivre mais sur son « coût » (et je ne parle pas de $$$).
Le coût d’une route est en fait la métrique du protocole OSPF et se base sur la bande passante de l’interface réseau.
Pour calculer le coût d’une interface, c’est plutôt simple. Il faut diviser une bande passante dite « de référence » qui vaut 100 000 000 bits/s (soit 10^8) par la bande passante de l’interface réseau transcrite en bits par seconde.
Voici un tableau pour mieux vous représenter cette notion de coût :
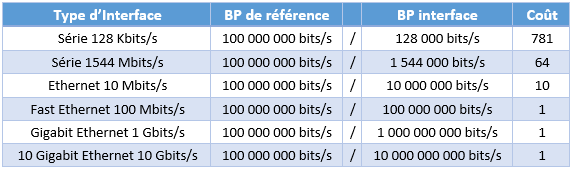
Plus le coût est faible, meilleure sera la route pour OSPF car il considère que la route sera celle supposément la plus rapide à la vue de son débit théorique.
|
Info ++ : Dans notre topologie de test, nous utilisons une topologie Point-à-point entre nos routeurs. En revanche, dans le cas d’une topologie « Broadcast multi-accès » (telle qu’Ethernet avec des switchs), OSPF risque d’inonder le réseau de messages inutiles. Pour pallier à ceci, les routeurs vont devoir élire un « Designated Router » (DR) qui sera le « chef » et qui lui seul transmettra les informations à tous les autres routeurs, et un « Backup Designated Routeur » (BDR) qui prendra la place du DR en cas d’indisponibilité de ce dernier. Plus d’infos sur cet article qui explique de façon simple ce processus : OSPF DR & BDR |
Bon assez de blabla, on passe à la pratique !
Reprenez une topologie sous Cisco Packet Tracer toute prête, sans routage bien sûr, et commençons par R1.
Activez le routage OSPF sur R1 avec la commande suivante en mode de configuration (commandes « en » et « conf t » préalables) :
router ospf 1 |
Le 1 ici représente l’ID de processus OSPF. C’est une valeur locale propre au routeur. Ce n’est pas obligatoire d’avoir la même sur tous les autres routeurs mais dans le cadre de ce tuto, on gardera la même.
Ensuite, nous allons déclarer les réseaux de routeurs connus par R1, soit le réseau A et le réseau B. La commande prend la forme suivante :
network [ip_réseau] [masque_inversé] area [ID_zone]
Je vous rappelle que OSPF fonctionne par zone (area), la zone déclarée ici devra donc être la même sur tous les routeurs de notre topologie.
Le « masque inversé », ou « wildcard mask » est utilisé par le protocole OSPF et lui sert à identifier les réseaux et sous-réseaux, comme un masque normal à la différence qu’il s’écrit… à l’inverse !
Voici un exemple :
Un masque en 255.255.255.0 implique que les 24 premiers bits sont à 1 et les 8 derniers à 0, c’est-à-dire qu’on peut l’écrire en binaire de cette façon 11111111.11111111.11111111.00000000.
Pour un masque inversé, les bits à 1 passent à 0 et les bits à 0 passent à 1. Ce qui veut dire qu’en binaire on écrira 00000000.00000000.00000000.11111111 soit 0.0.0.255 en décimal. Le wildcard masque du masque 255.255.255.0 sera donc 0.0.0.255.
L’ID de la zone (area) est le numéro de la zone dans laquelle nous voulons placer l’interface pour qu’elle échange avec les autres routeurs. Cette area sera commune à tous les routeurs de la topologie.
Pour R1, nous pouvons donc saisir les commandes suivantes :
network 192.168.1.0 0.0.0.255 area 0network 192.168.2.0 0.0.0.255 area 0 |
Nous avons déclaré en configuration OSPF, au routeur R1, qu’il connaissait les réseaux de routeurs A et B.
Et comme avec le protocole RIP, vous pouvez déclarer également le réseau D qui est lui aussi connecté à R1 ou utiliser simplement la commande de redistribution suivante :
redistribute connected |
Le protocole OSPF a bien été configuré sur R1 ! Passons à R2, voici donc les commandes à saisir :
router ospf 1network 192.168.1.0 0.0.0.255 area 0network 192.168.3.0 0.0.0.255 area 0redistribute connected |
Et pour R3… à vous de jouer !
N’oubliez pas de faire des pings à partir de et en direction des 3 ordinateurs pour vérifier que la communication est opérationnelle.
|
Info + : La 5ème partie de la vidéo (dispo ICI) montre la configuration du routage OSPF qui vient d’être effectuée. |
Vérifions la table de routage de l’un de nos routeurs :
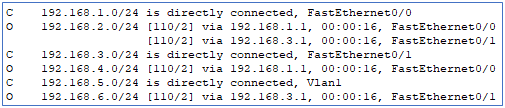
Pour vérifier la base de données du protocole OSPF, lancez la commande suivante :
show ip ospf database |

Et pour vérifier les relations de voisinage d’un routeur utilisant OSPF, utilisez la commande :
show ip ospf neighbor |

3. Le protocole EIGRP
Passons à un 3ème et dernier protocole à découvrir : le protocole EIGRP (Enhanced Interior Gateway Routing Protocol)
La première chose à savoir sur EIGRP, c’est qu’il est à la fois protocole à vecteur de distance et à état de lien. On parle d’un protocole de routage hybride.
C’était à la base un protocole propriétaire de Cisco qu’il n’était pas possible d’utiliser sur du matériel d’autres constructeurs. Le protocole s’est ouvert au monde depuis 2013.
|
Info + : Le protocole de routage EIGRP utilise l’algorithme DUAL. Sa distance administrative est de 90 et il ne supporte pas plus de 224 sauts. |
Il fonctionne sur le même principe qu’OSPF et utilise des systèmes autonomes comme moyen d’authentification pour échanger des données avec d’autres routeurs. Il établit lui aussi des relations de voisinage en envoyant des messages de type « hello » dans son système autonome.
Il va stocker dans une table de voisinage les données transmises par les routeurs voisins. Ensuite il va transmettre ses propres informations de routage à tous les membres de son système autonome.
Une fois toutes les infos des différents routeurs réceptionnées, chaque routeur connaîtra l’ensemble de la topologie du réseau. Ce sera ensuite à l’algorithme utilisé par EIGRP de choisir la meilleure route pour accéder à un réseau x ou y.
La différence avec les autres protocoles, c’est qu’il n’utilise pas le nombre de sauts pour aller sur une destination particulière mais il tient compte de la bande passante du lien (comme OSPF), de la charge de la liaison, de sa fiabilité mais aussi du délai de transmission.
EIGRP est un protocole de routage à convergence rapide, très puissant, capable de gérer IPv4 et IPv6 et qui se déploie très facilement.
Voyons cela ! Activez le routage EIGRP sur R1 avec la commande suivante en mode de configuration (commandes « en » et « conf t » préalables) :
router eigrp 10 |
Le 10 ici représente le numéro de système autonome qui devra être identique sur les 3 routeurs pour qu’ils s’échangent des informations de routage
Ensuite, on déclare les réseaux de routeurs connus par R1, soit le réseau A et le réseau B. La commande prend la forme suivante :
network [ip_réseau]
Les commandes à saisir sont :
network 192.168.1.0network 192.168.2.0 |
Vous le voyez, pas de notion de masque ou de zone ici, juste une déclaration simple des réseaux connus, comme pour le protocole RIP.
Et une fois encore, soit vous ajouter une commande pour chaque réseau connu par le routeur, soit vous appliquez la redistribution des réseaux connectés avec la commande :
redistribute connected |
Voilà pour R1 ! Et maintenant les commandes pour R2 :
router eigrp 10network 192.168.1.0network 192.168.3.0redistribute connected |
Et pour R3, je pense que vous avez compris que vous devez vous débrouiller seul. 
On n’oublie pas de tester que le routage fonctionne sur votre topologie !
|
Info + : La dernière partie de la vidéo (dispo ICI) montre la configuration du routage EIGRP qui vient d’être effectuée. |
Une fois encore, regardons la table de routage d’un routeur :

Regardons la relation de voisinage d’un routeur sous EIGRP avec la commande :
show ip eigrp neighbors |

Et affichons la topologie du réseau connu par un routeur avec la commande :
show ip eigrp topology |

Pour aller plus loin
Sachez qu’il existe plusieurs de protocoles de routage différents. Certains sont dits Intérieurs et d’autres Extérieurs. C’est-à-dire qu’ils sont capables de connecter des systèmes autonomes différents entre eux. Ils possèdent tous des distances administratives différentes.
Le protocole de routage BGP par exemple, le plus utilisé sur le réseau Internet, est un protocole externe. Vous pouvez également croiser les protocoles IS-IS ou IGRP…
Ceci conclut ce long article sur le routage dynamique ! N’hésitez pas à créer votre propre topologie sous Cisco Packet Tracer avec de plus en plus de routeurs pour bien comprendre le fonctionnement des protocoles.
Quant à moi, je vous dis à très vite ! 
![Introduction au routage IP [+vidéo]](https://neptunet.fr/wp-content/uploads/2020/01/illust-post-routage.png)
![[Tuto] Simuler de la VOIP sur Cisco Packet Tracer (+ vidéo)](https://neptunet.fr/wp-content/uploads/2019/09/illust-post-voip1.png)
