

Ce qui fait aujourd’hui qu’on arrive à transmettre des paquets de données d’un réseau A vers un réseau B c’est ce qu’on appelle le routage IP.
Le routage s’appuie sur des protocoles pour mener à bien sa mission. Mais concrètement le routage IP, ça fonctionne comment ?
Et bien c’est ce qu’on va voir grâce à ce 1er article qui va mettre l’accent sur le routage statique… 
Initiation au routage IP et mise en place du routage statique
Histoire de bien commencer cet article, avant de parler de routage, on va parler de… routeur ! (Oui parce que moi j’aime pas faire les choses dans l’ordre !  )
)
Pour donner une définition générale de ce qu’est un routeur on pourrait dire que c’est un équipement intelligent de réseau (équivalent à un ordinateur) dédié à l’envoi de paquets à travers un réseau de données.

Le rôle d’un routeur est d’interconnecter les réseaux entre eux en sélectionnant le meilleur chemin, la meilleure route à suivre, pour qu’un paquet arrive à sa destination finale.
C’est un peu comme une intersection routière avec des panneaux signalétiques qui indiquent le chemin vers plusieurs directions !
Et pour que les routeurs puissent faire correctement leur travail, à savoir donc transférer des paquets d’un réseau à un autre, il faut leur indiquer une méthode pour connaître les chemins vers des destinations diverses, méthode qu’ils vont consigner dans ce qu’on appelle leur « table de routage ». La table de routage est un peu la base de données du routeur contenant les chemins vers différents réseaux.
Et c’est là qu’intervient le routage IP ! On parle d’un mécanisme grâce auquel le meilleur chemin sera sélectionné pour acheminer des données qu’on appelle techniquement à ce niveau des « paquets » ou des « datagrammes ».
|
Info + : Le routage IP intervient au niveau de la couche 3 Réseau du modèle OSI (couche Internet du modèle TCP/IP) |
Les datagrammes sont en réalités des données « encapsulées », c’est-à-dire auxquelles ont été ajoutées des « entêtes IP » contenants entre autres des informations permettant d’assurer le routage.

Un entête IP fait 20 octets, soit 160 bits (1 octet = 8 bits). Il est représenté graphiquement dans un tableau comprenant 5 lignes de 32 bits chacune (ce qui nous donne 5 lignes x 32 bits = 160 bits / 8 bits = 20 octets, le compte est bon !).
Voici l’illustration la plus célèbre d’un entête IP représenté avec tous ses champs (hors options) :
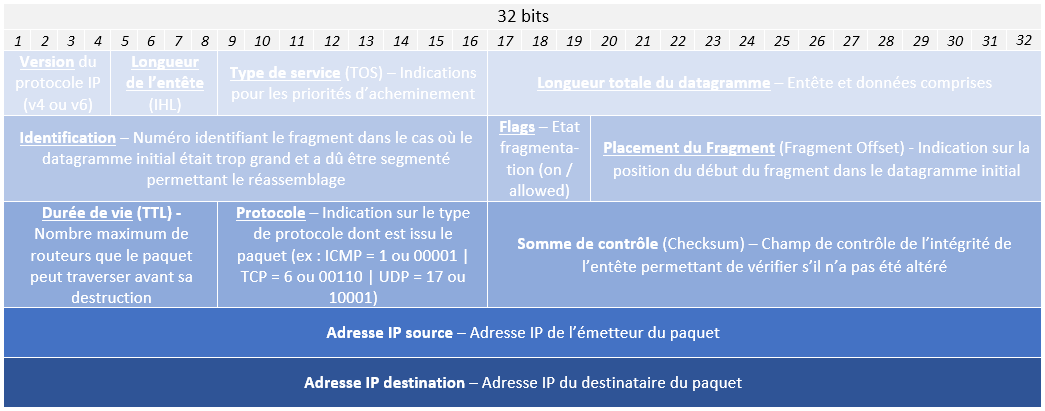
Dans notre contexte, les champs qui vont nous intéresser seront les suivants :
- Durée de vie : aussi appelé le Time To Live (TTL) qui permet de définir le nombre maximal de routeur que le paquet pourra traverser avant d’être abandonné. Ce champ comprend un nombre qui sera décrémenté à chaque fois que le paquet passera par un routeur.
- Adresse IP source : permettant de connaître l’adresse IP de l’émetteur du paquet pour éventuellement lui envoyer une réponse
- Adresse IP destination : permettant de connaître l’adresse IP du destinataire (et par conséquent son réseau) afin de lui transmettre le paquet
|
Info + : Je ne rentrerai pas dans les détails des autres champs de l’entête IP et je vous conseille une nouvelle fois de vous tourner vers l’excellent site FrameIP pour plus d’infos : Entête IP. Vous découvrirez qu’un entête IP pour contenir 4 octets supplémentaires dans le cas d’utilisation d’options spécifiques. |
Avec ces informations, voyons concrètement ce qu’il se passe quand un paquet arrive sur un routeur :
- Le routeur va lire l’entête IP du paquet pour identifier sa destination
- Le routeur va vérifier dans sa table de routage si il a une indication sur le chemin à suivre pour aller sur le réseau de destination.
- Le routeur peut alors ensuite :
- Transférer le paquet directement au destinataire si il se trouve dans le même réseau que lui
- Transférer le paquet à un autre routeur sachant comment arriver au destinataire
- Transférer le paquet à un autre routeur défini comme étant le routeur par défaut auquel effectué les transferts quand aucun chemin précis n’est indiqué
- Abandonner le paquet si il n’a aucune indication précise
Et parce qu’il n’y a rien de plus parlant qu’une bonne démo, je vous propose de réaliser la mise en pratique du routage statique (c’est-à-dire manuel) sur une infrastructure très simple.
|
Info ++ : Cet article ne traitera pas du routage dynamique et de ses protocoles associés. Voir l’article suivant traitant du sujet : Routage IP Dynamique |
Débuter par le routage statique est la meilleure solution pour bien visualiser la façon dont le routage s’articule.
Voici le schéma de mon infrastructure :
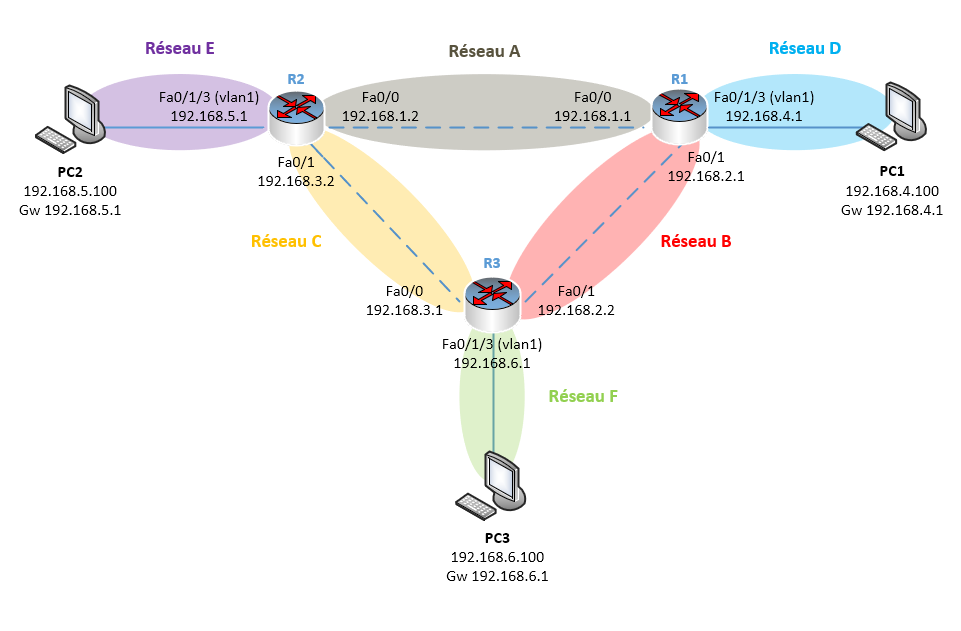
Comme vous le voyez, on a un total de 6 réseaux différents que voici :
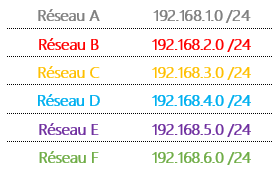
Nous avons trois réseaux comprenant chacun un PC et 3 réseaux de routeurs car, oui, entre 2 routeurs, c’est un réseau également (si tous les équipements ont des adresses IP dans le même réseau, le routage devient inutile puisque nous n’avons plus besoin de changer de réseau, ce qui est justement, l’intérêt du routage…).
Le but ici sera que les PCs qui sont sur des réseaux différents puissent communiquer entre eux (par de simple tests de ping). Il faudra donc indiquer aux routeurs les chemins sur lesquels ils devront envoyer les paquets de données pour arriver à bonne destination !
Plus clairement, il faudra leur indiquer la route à suivre pour aller d’un point A, vers un point B.
Petite précision :
Pour réaliser cette topologie sous Cisco Packet Tracer, j’ai dû ajouter des ports réseaux supplémentaires aux routeurs qui par défaut n’en possède que deux.
J’ai choisi de mettre des ports de switch (c’est uniquement histoire d’introduire le concept de VLAN…) mais vous pouvez tout à fait jouter un seul port Ethernet et lui attribuer directement une adresse IP !
![]()
Comme ce sont des ports de switch, on ne peut pas attribuer d’adresse IP à ces interfaces. J’ai donc attribué une adresse IP au VLAN numéro 1 dans lequel toute les interfaces sont par défaut.
Un VLAN, pour rester très simple, c’est un réseau local virtuel (virtual LAN).
Dans ce réseau virtuel on inclut des ports du switch qui feront donc parti dudit réseau. Tous les équipements branchés sur un port appartenant par exemple au VLAN 10 devront posséder une adresse IP du même réseau que le VLAN 10 pour communiquer dans son propre réseau.
C’est exactement comme un port de routeur tout à fait normal, « physique », sauf qu’on est sur du logique, du « virtuel ». L’adresse IP du VLAN 10 deviendra donc la passerelle de sortie du réseau.
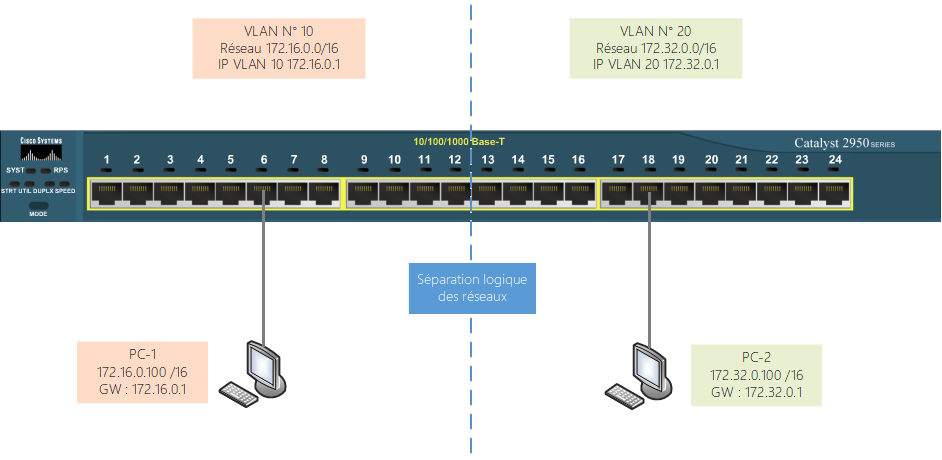
Dans l’illustration précédente, nous avons un switch sur lequel on a séparé les ports en 2 VLANs distincts.
Les machines connectées aux ports 1 à 12 seront sur le réseau 172.16.0.0/16 car ces ports appartiennent au vlan n° 10, et les machines connectées aux ports 13 à 24 seront sur le réseau 172.32.0.0/16 car ces ports appartiennent au vlan n°20.
Les deux réseaux ne peuvent pas communiquer entre eux dans l’état actuel, il faudra activer le routage inter-vlan sur le switch (ce n’est pas le sujet de notre article mais au cas où, la commande pour un switch est « ip routing », je dis ça, je ne dis rien !)
Voilà pour ces petites explications pour se mettre en jambes !
Maintenant, il faut créer la topologie que l’on va utiliser sous Cisco Packet Tracer. Dans les 2 premières parties de la vidéo ci-dessous, vous pourrez voir comment j’ai intégralement créé l’infrastructure pour vous aider à la reproduire.
|
Info ++ : Je vous conseille de lire la suite de cet article avant d’aller plus loin dans la vidéo car elle couvre des concepts que vous ne connaissez peut être pas encore… |
Une fois prêt, vous pouvez passer à la mise en application du routage IP ! Assurez-vous bien que vos PCs pinguent leur passerelle respective avant d’aller plus loin.
Configuration du routage statique
Comme son nom l’indique, le routage sera fixe. C’est-à-dire qu’il ne sera pas automatiquement mis à jour. Il implique que l’administrateur réseau renseigne lui-même les routes à prendre sur chaque routeur pour aller sur tel ou tel réseau.
Reprenons notre schéma pour construire mentalement la table de routage de chaque routeur :
Démarrons avec le routeur R1 situé en haut à droite et listons les informations que nous connaissons sur lui, c’est-à-dire les réseaux qu’il connait déjà puisqu’il y est directement connecté :
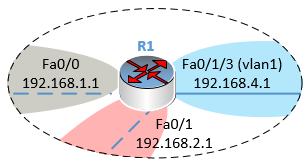

Les réseaux A, B et D sont propres au routeur R1, il n’est donc pas nécessaire de lui dire que pour aller sur le réseau A, B ou D, il doit passer par lui-même…
Listons donc maintenant les réseaux de l’infrastructure qu’il ne connait pas :

L’administrateur réseau va donc devoir dire au routeur R1 que pour envoyer des paquets de données vers les réseaux C, E et F, il devra les transmettre à tel ou tel autre routeur.
Pour savoir quel routeur sera ce qu’on appelle le « saut suivant », c’est-à-dire le routeur auquel les paquets seront transférés, il faut faire le chemin tout simplement et regarder quels sont les routeurs à traverser pour arriver à bonne destination.
Le second routeur, qui a forcément une interface dans le même réseau que le premier routeur (ben oui sinon ils ne se connaissent pas donc le routeur 1 ne pourra envoyer les infos au routeur 2 !), et qui permettra d’effectuer le meilleur chemin, deviendra le saut suivant.
Dans notre infrastructure, si PC1 souhaite envoyer un paquet à PC2, il commencera par transmettre le paquet à la passerelle de son propre réseau, c’est-à-dire à R1 (1).
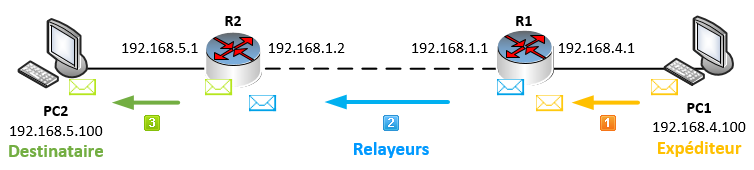
Ensuite, R1 doit transférer le paquet au routeur le plus proche du réseau de destination dans notre infrastructure, voire même mieux, au routeur qui appartient au réseau de destination ! Souvenez-vous, le rôle du routeur c’est de choisir le meilleur chemin possible pour faire transiter les paquets ! Dans notre cas, il s’agit donc de R2 (2).
R2 sera donc le saut suivant de R1.
Comme R2 est dans le même réseau que PC2 qui est le destinataire, celui-ci n’aura plus qu’à lui envoyer le paquet directement (3).
Mettons cela dans un tableau représentant la table de routage de R1 :
![]()
Si vous avez compris le concept, vous devriez pouvoir établir la route pour que le routeur R1 transfèrent les paquets à destination des réseaux C et F auxquels il n’est pas directement connecté. Ce qui vous donnera la table de routage suivante :

La commande pour appliquer une route statique sur un routeur Cisco à la forme suivante :
ip route [réseau_destination] [masque_destination] [ip_routeur_suivant]
Pour notre routeur R1, on aura donc les commandes suivantes à saisir en mode de configuration (commande « conf t » préalable) :
ip route 192.168.3.0 255.255.255.0 192.168.1.2ip route 192.168.5.0 255.255.255.0 192.168.1.2ip route 192.168.6.0 255.255.255.0 192.168.2.2 |
Alors là vous devriez me dire « oui mais attends, pour que R1 puisse envoyer vers le réseau C, moi j’ai mis comme saut suivant 192.168.2.2 ! Et ça marche quand même ! »
Et vous aurez raison !
Le fait est que pour aller sur certains réseaux, plusieurs chemins sont possibles. Le but étant que le chemin emprunté soit le plus simple et donc le rapide !
Dans le cas du routeur R1 vers le réseau C, les deux chemins sont possibles avec la même « métrique » c’est-à-dire avec le même nombre de saut avant d’arriver à destination (la même distance en résumé), à savoir 1 seul saut. Les deux solutions sont donc justes et je dirais même plus, les deux sont nécessaires.

Ajouter une route secondaire vers une destination est un moyen de pallier à une panne ! Imaginons que le routeur R2 soit en panne. Le routeur R1 se retrouvera alors dans l’impossibilité d’aller vers le réseau C (même si dans notre topologie actuelle, ça ne sert à rien… mais imaginez un réseau bien plus grand !).
La solution c’est d’ajouter le routeur R3 comme route secondaire. On parlera alors de « route statique flottante ». Ce sera la route qui prendra le relais en cas de rupture de la liaison définie initialement.
La commande pour ajouter une route statique flottante aura alors la forme suivante :
ip route [réseau_destination] [masque_destination] [ip_routeur_suivant] [distance_administrative]
Une notion importante dans le routage est la notion de « distance administrative ».
La distance administrative est une donnée sous forme de nombres utilisée par un routeur afin de déterminer quel est le meilleur chemin à emprunter.
Chaque route (qu’elle soit statique ou dynamique) possède un numéro de distance administrative.
Plus la distance administrative d’une route est basse, plus la route sera considérée comme « fiable ». La route la plus fiable sera donc celle empruntée en priorité par le routeur pour acheminer les paquets.
Il faut savoir qu’un routeur peut utiliser en simultanée plusieurs protocoles de routage différents. Chaque protocole de routage possède par défaut sa propre distance administrative.
Pour une route directement connectée, la distance administrative sera de 0.
Pour une route statique, la distance administrative sera de 1.
Si nous voulons ajouter une route flottante pour que le routeur R1 puisse aller sur le réseau C dans le cas où le routeur R2 est inaccessible, il faudra donc déclarer la seconde route et la distance administrative que l’on veut définir pour cette route secondaire.
|
Info ++ : Attention, si les deux routes ont la même distance administrative, on s’expose à une perte de paquets ! Faites le test par vous-même en ajoutant les deux chemins possibles sur R1 à destination du réseau C sans préciser de distance administrative et lancer des pings sur les différentes IP du réseau C, vous verrez que les pings ne passent jamais à 100%… |
C’est pourquoi on ajoute à la route flottante, une distance administrative supérieure à 1. On peut tout simplement mettre une distance administrative de 2 dans notre contexte, ce qui donnera la commande supplémentaire suivante sur R1 :
ip route 192.168.3.0 255.255.255.0 192.168.2.2 2 |
En résumé, cette route ne sera utilisée que dans le cas où la 1ère ne serait pas fonctionnelle.
Revenons-en à la base ! Vous avez maintenant dû ajouter vos routes statiques sur le routeur R1. Pour afficher la table de routage sous Cisco, la commande est (hors mode de configuration) :
show ip route |
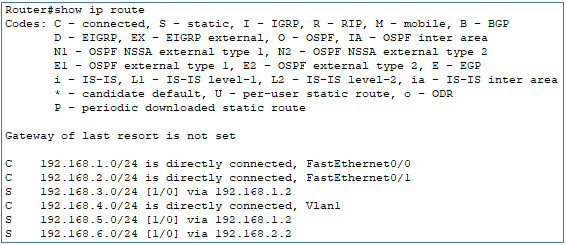
La partie supérieure renvoyée par cette commande nommée « Codes », est la légende de la table de routage. La route commençant par la lettre C est une route « connected », S « static », etc…
Bien, maintenant, il faut faire la même chose pour le routeur R2 !
On recommence notre réflexion. Notons les réseaux directement connectés à R2 dans un tableau.
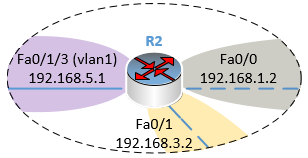
Ce qui nous donnera forcément, la liste des réseaux qu’il ne connait pas :

Maintenant, on regarde bien la topologie et on recherche les chemins à emprunter pour que R2 transfère bien les paquets de données à destination de ces 3 derniers réseaux.
La table de routage de R2 sera la suivante :

Les commandes à saisir sur le routeur R2 seront donc :
ip route 192.168.2.0 255.255.255.0 192.168.1.1ip route 192.168.4.0 255.255.255.0 192.168.1.1ip route 192.168.6.0 255.255.255.0 192.168.3.1 |
Et enfin… il faut faire pareil sur le routeur R3 !
A ce stade, vous devriez être en mesure de le faire seul ! Essayez avant de poursuivre votre lecture… (et ne trichez pas !)
Les réseaux connus par R3 :
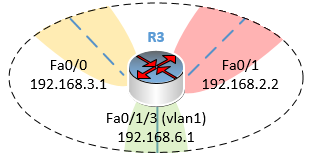

Les réseaux que R3 doit joindre :

Et la table de routage de R3 :

Je ne remets pas les commandes à saisir sur le routeur, vous avez compris le truc 
La 3ème partie de la vidéo (dispo ICI pour ceux qui ont la flemme de remonter…) montre la configuration du routage statique qui vient d’être effectuée.
Faites des tests de ping dans tous les sens pour vous assurer que le routage fonctionne correctement.
N’hésitez pas également à utiliser traceroute (commande tracert) pour visualiser chaque équipement par lequel votre paquet de données va passer.
Quand votre routage statique fonctionne, vous êtes prêt pour le routage dynamique qui fera l’objet d’un prochain article… 
La route par défaut
Autre point important dans la configuration du routage (et qui simplifie grandement la vie), la « route par défaut ».
La route par défaut est représentée comme ceci :
0.0.0.0 0.0.0.0 [saut_suivant]
Son but est de dire :
« Pour aller sur n’importe quel réseau (soit 0.0.0.0 avec le masque 0.0.0.0) passe par le router x (ou x est l’adresse IP du prochain routeur, le « saut suivant ») »
On peut s’en servir notamment pour aller vers le réseau internet.
Reprenons notre infrastructure de base et transformons-la quelque peu (vous n’êtes pas obligé de réaliser cette partie de l’article, je ne détaillerai pas ici la mise en place de l’infra, il faut juste que vous reteniez ce qu’est une route par défaut et comment on l’utilise).
On va ajouter un 4ème routeur qui sera connecté à la fois à deux réseaux locaux et également à internet (on parle de LAN pour un réseau local, « Local Area Network », et de WAN pour le réseau internet, « Wide Area Network »), que nous appellerons NAT.
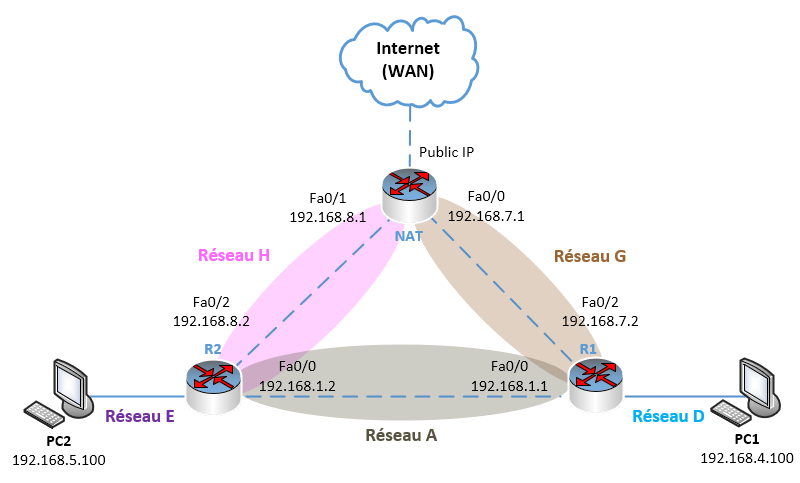
Je vous rappelle qu’un lien entre deux routeurs EST un réseau donc dans la topologie ci-dessus, on voit apparaître deux nouveaux réseaux en plus :
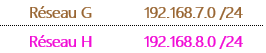
Et comme le routeur NAT a une interface directement connectée sur internet, son adresse IP est attribuée automatiquement par le fournisseur d’accès à internet (FAI), c’est donc l’adresse IP public de notre infrastructure qu’on ne gère pas.
Comme il est impossible de connaître l’ensemble des réseaux sur internet, (et même si c’était possible, on ne va pas renseigner des milliers de routes sur nos routeurs quand même !), c’est là que la route par défaut va intervenir.
Imaginons que PC2 envoie un paquet à destination d’une adresse IP située sur internet (vers l’adresse 8.8.8.8 par exemple).
PC2 transfère son message à sa passerelle qui est R2. R2 lit la trame et regarde l’adresse de destination. Il vérifie dans sa table de routage pour savoir où envoyer le paquet.
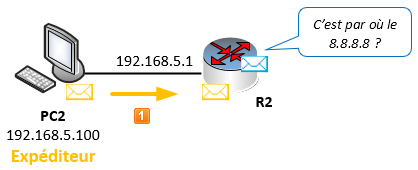
Aucune route n’est définie pour l’adresse réseau de destination sur R2. Il va donc devoir s’appuyer sur l’adresse IP du saut suivant défini dans sa route par défaut (« gateway of last resort ») et lui transférer le paquet.
Dans notre infrastructure, le saut suivant de R2, pour aller sur n’importe quel réseau (0.0.0.0/0) sera l’adresse IP dans le même réseau que R2, du routeur NAT soit 192.168.8.1, puisque c’est le routeur NAT qui est directement connecté à Internet. C’est donc lui qui peut transmettre les paquets le plus « largement », c’est-à-dire n’importe où vers internet…
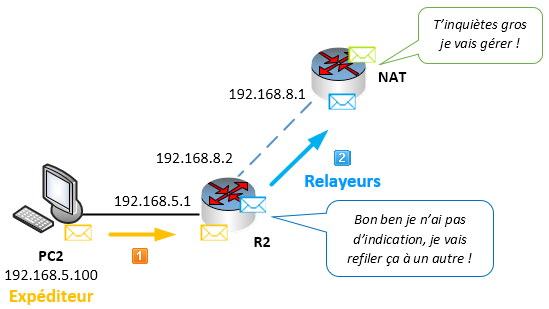
La commande à saisir sur le routeur R2 pour définir sa route par défaut sera la suivante :
ip route 0.0.0.0 0.0.0.0 192.168.8.1 |
Cette commande dit textuellement :
« Pour aller sur n’importe quel réseau qui n’est pas dans la table de de routage, passe par l’adresse IP 192.168.8.1 (le routeur NAT). »
Jetons un coup d’œil à la table de routage de R2 après l’ajout de la route par défaut :
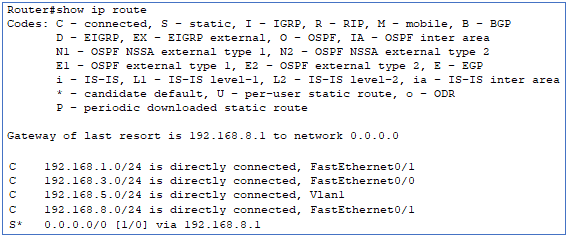
On retrouvera donc en « gateway of last resort », la route que l’on vient de configurer.
Le paquet en partance de PC2 sera donc acheminé par le routeur NAT, qui l’enverra à un autre ami routeur, puis un autre, puis encore un autre… et ainsi de suite jusqu’à l’adresse du destinataire.

Si aucune entrée dans la table de routage n’existe pour aller sur le réseau de destination ou qu’aucune route par défaut n’est définie, le paquet sera purement et simplement abandonné.
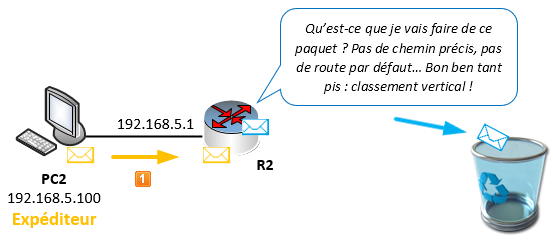
Une route par défaut n’est pas réservée spécifiquement pour aller vers internet, elle permet également d’éviter de saisir 500 routes pour aller d’un point A vers un point B, C, D, T, Y, W, Z… qui ne seront pas forcément utiles.
Voilà pour cette 1ère introduction au routage IP et aux routes statiques !
Vous savez désormais comment vos paquets de données transitent d’un réseau à l’autre !
A bientôt ! 
![Introduction au routage IP dynamique [+vidéo]](https://neptunet.fr/wp-content/uploads/2020/03/illust-post-routage2.png)
![[Tuto] Simuler de la VOIP sur Cisco Packet Tracer (+ vidéo)](https://neptunet.fr/wp-content/uploads/2019/09/illust-post-voip1.png)
